Building a Production-Ready Microservice Backend_ Architecture, Patterns, and Scaling
A deep-dive into the system design of a real-world event platform with real-time capabilities, financial transactions, and multi-tenant access control
Table of Contents
- Overview
- The Monorepo Decision
- Service Architecture and Responsibility Boundaries
- Database Layer — Schema Separation, Not Service Separation
- gRPC Inter-Service Communication — Why Not HTTP?
- Redis — Four Roles in One Instance
- The Job Processor — Worker / Gateway Split
- The Escrow State Machine and Financial Architecture
- Authentication Architecture
- Security Layers — Defence in Depth
- The Async Event Lifecycle
- Frontend Integration — The Next.js Rewrite Pattern
- File Uploads — The Presigned URL Pattern
- Countdown Timers — Drift-Corrected Client-Side Ticking
- Infrastructure and Deployment
- Capacity Analysis — How Many Users Before Something Breaks?
- Scaling Additions — When and How
- Non-Obvious Design Decisions
- Shared Library Design — The @shared Module
- Observability Recommendations
1. Overview
This article is a complete architectural walkthrough of a production-ready backend system built to handle real-time events, financial transactions, async job processing, WebSocket broadcasting, and multi-tenant access control — all at the same time and at scale.
Rather than a “how to build a REST API” tutorial, this is a case study of how architectural decisions compound: why gRPC was chosen over HTTP for inter-service calls, how Redis serves four completely different roles in the same system, why the job processor is split into two separate modes, what the real upper bound of concurrent users looks like before any infrastructure upgrade is needed, and how a presigned URL pattern offloads file upload bandwidth entirely from the application servers.
The tech stack:
- Node.js 20 + NestJS 11 — Backend framework
- TypeScript 5.9 — Strict everywhere, no any
- PostgreSQL 15 — Primary database with dual schema separation
- Redis 7 — Queues, cache, WebSocket adapter, atomic counters
- gRPC (protobuf over TCP) — Inter-service communication
- Bull — Redis-backed job queues
- Socket.IO — Real-time WebSocket layer
- Traefik v2 — Reverse proxy, TLS, rate limiting
- Docker + Docker Compose — Containerised, multi-stage builds
- Next.js 15 — Frontend (React 19, Tailwind CSS 4.1)
- Hetzner Cloud — Production infrastructure
2. The Monorepo Decision
The entire backend lives in a single pnpm monorepo with three independently deployable NestJS applications:
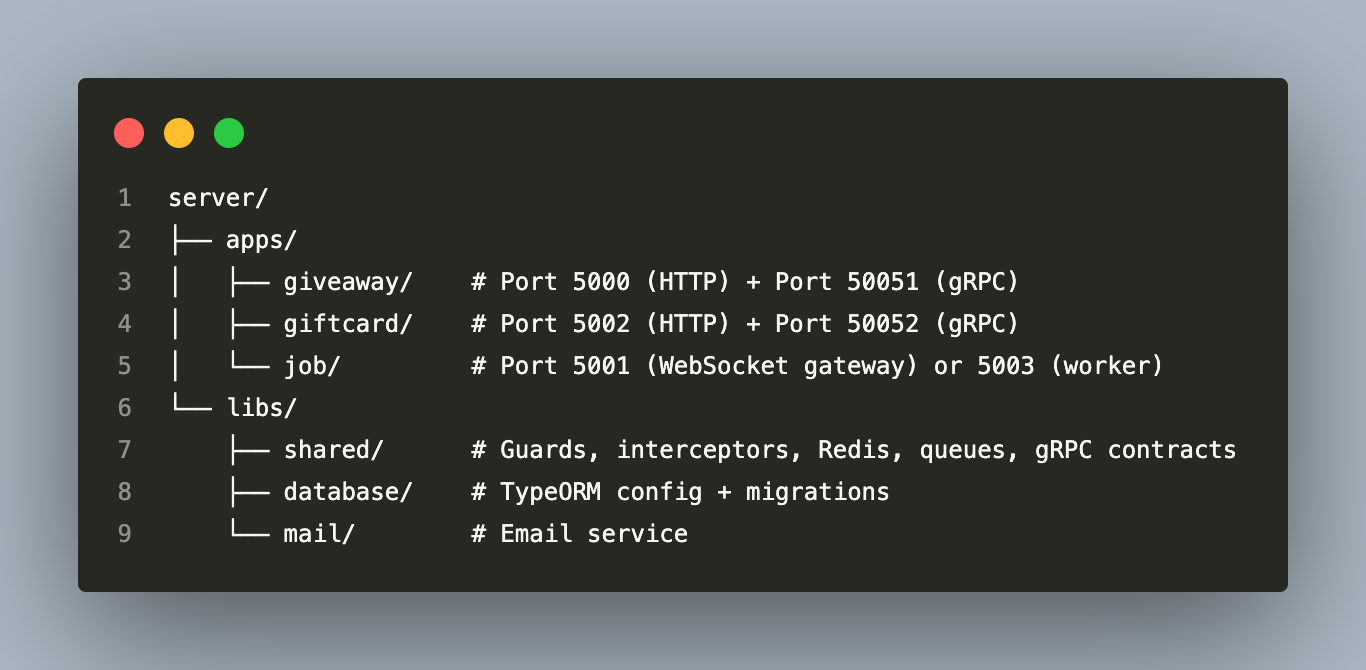
The monorepo is managed by a single nest-cli.json and shares TypeScript path aliases (@shared/*, @db/*, @mail/*). All three apps compile from one build step, yet deploy as independent Docker containers.
Why a monorepo over separate repositories?
The three apps share non-trivial infrastructure code: gRPC proto definitions and their TypeScript contract types, JWT guards, interceptors, the payment service client, queue configuration, and all TypeORM migrations. In separate repos, every change to a shared guard would require coordinated version bumps across three repositories. The monorepo eliminates that coordination cost without sacrificing deployment independence.
The tradeoff is that a bad merge can theoretically break all three apps simultaneously. This is mitigated with CI that builds all three on every PR — a compile failure on any app blocks the merge.
3. Service Architecture and Responsibility Boundaries
The Three Applications
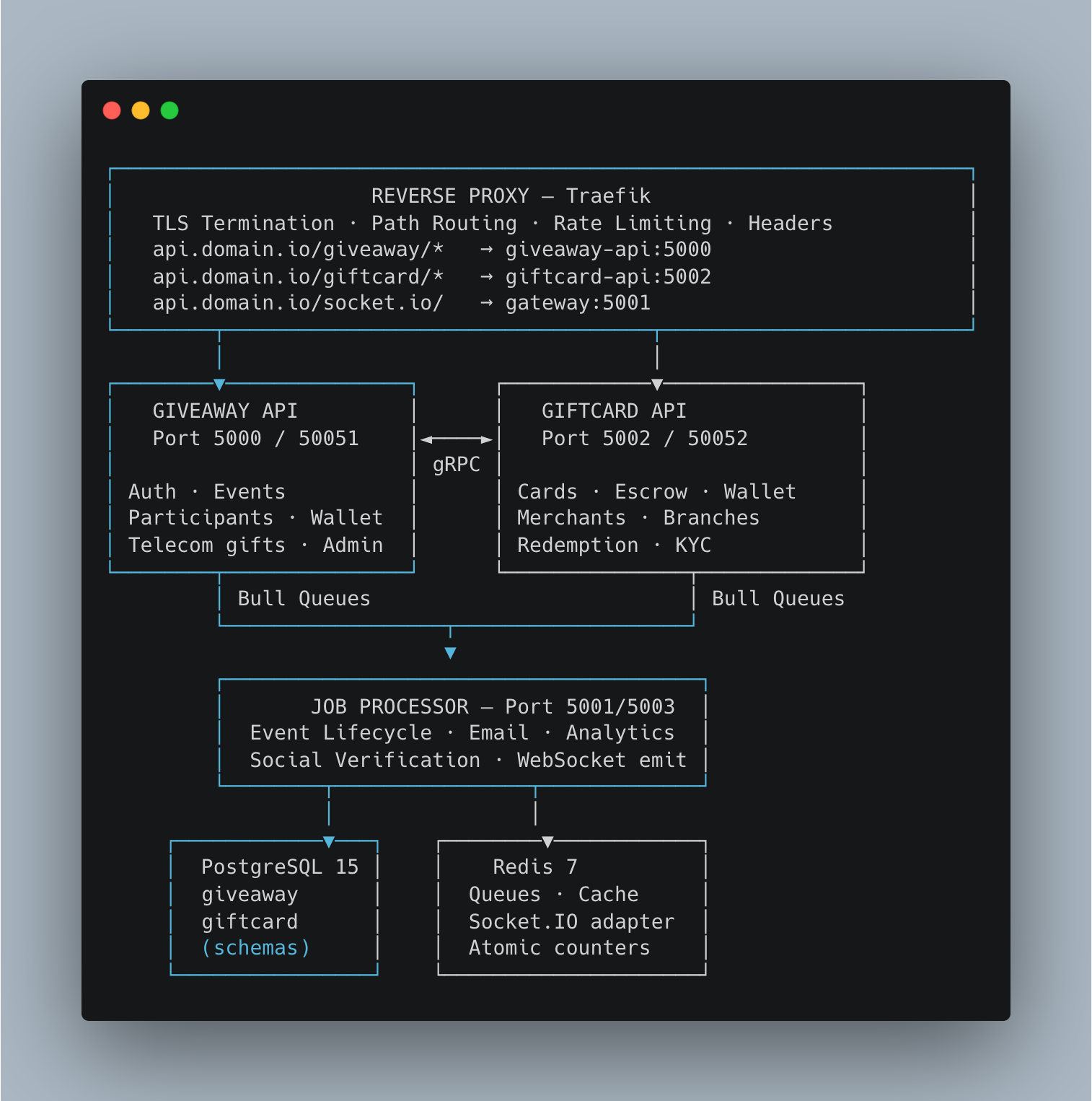
Giveaway API owns user identity, the event lifecycle (draft → scheduled → active → past), participant registration, social condition verification, host wallet management, telecom gift vending, and the admin control plane. It is also the gRPC server for the GiveawayService and AuthService.
Giftcard API owns the gift card marketplace: card definitions, merchant profiles (KYC), branch management, escrow-backed prize allocation, physical redemption at branches, and merchant wallet settlement. It exposes the GiftcardService gRPC server.
Job Processor owns no HTTP surface. It processes background work enqueued by the API services via Bull queues: emails, analytics logging, event status transitions, social media API verification calls, and WebSocket broadcasts. It runs in two distinct modes (more on this in section 7).
The critical rule: all cross-service data exchange goes through gRPC. Neither app ever directly queries the other’s database or injects the other’s services. This is a hard architectural constraint enforced at code review and by the fact that TypeORM DataSource instances are scoped per application — you cannot even reference the other service’s entities at compile time.
4. Database Layer — Schema Separation, Not Service Separation
The single PostgreSQL 15 instance is split into two logical schemas, not two separate databases:

Every TypeORM entity declares its schema explicitly:
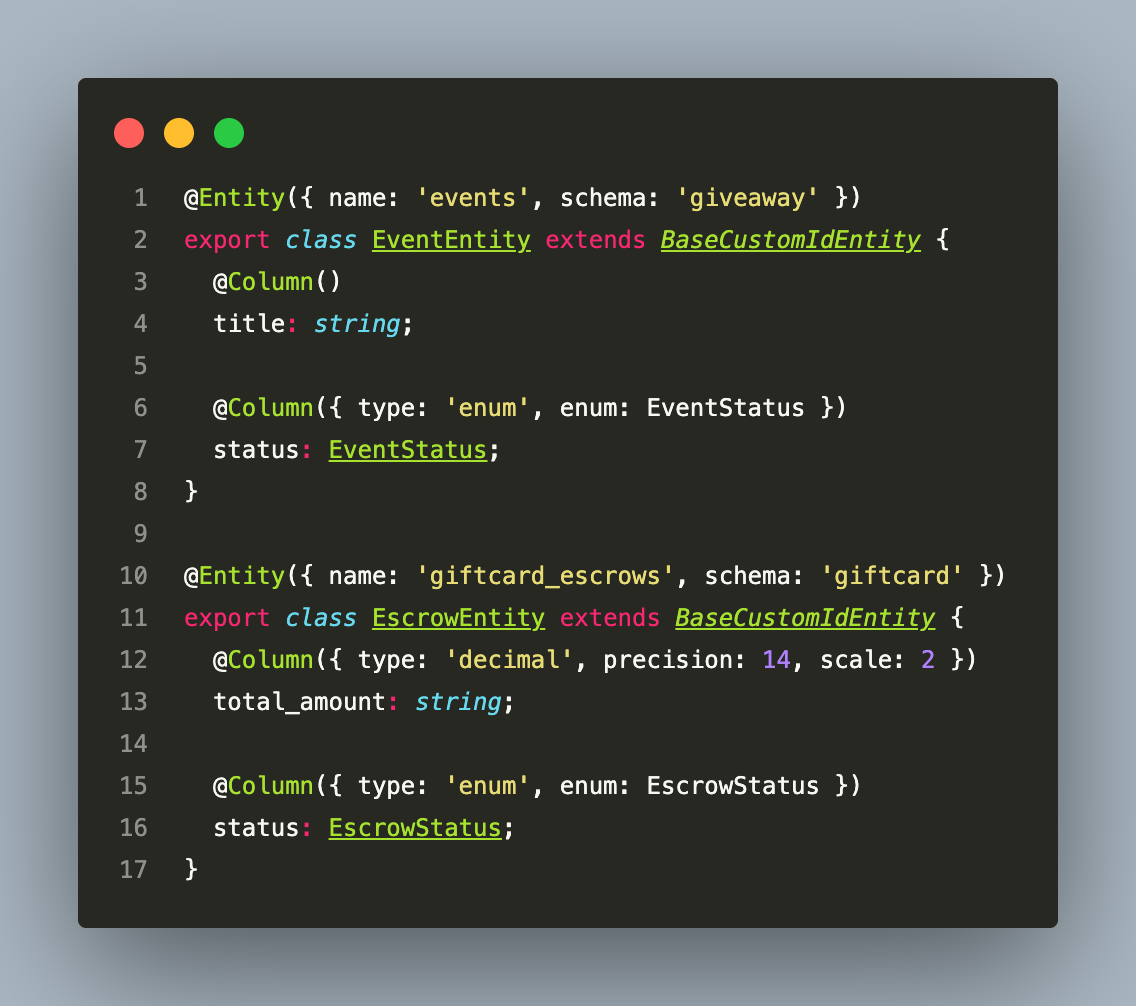
synchronize: false everywhere. All schema changes go through versioned TypeORM migrations, never auto-sync. The TypeORM DataSource has no search_path set — any unqualified table name fails at runtime, which makes cross-schema access impossible by accident.
Why one database, two schemas instead of two databases?
This is a pragmatic call for the current scale. A single PostgreSQL instance running on its own VPS with two schemas gives:
- One connection pool, one backup job, one upgrade window
- Zero cross-database join complexity (though cross-schema joins are intentionally not used — gRPC handles all cross-service data needs)
- Schema-level isolation: each service’s queries are scoped to their schema by entity declarations, not by runtime path settings
The tradeoff accepted: both services run migrations against the same physical database. A botched migration in one service’s schema could block the other service’s migration runner. As the system scales, separating into two databases becomes attractive; the gRPC boundary means that migration is purely operational, not code-level.
Entity ID Strategy
All entity IDs use a custom PREFIX-ULID format:

IDs look like EVENT_01ARZ3NDEKTSV4RRFFQ69G5FAV. The prefix makes log scanning and debugging dramatically easier — you immediately know what type of entity you’re looking at without a schema lookup. ULID is chosen over UUID because it is lexicographically sortable, which matters for index efficiency on time-ordered queries.
5. gRPC Inter-Service Communication — Why Not HTTP?
The Giveaway API and Giftcard API communicate exclusively via gRPC. The choice over REST HTTP deserves explanation because it is not the default intuition for NestJS applications.
The concrete reasons:
- Strongly-typed contracts. Proto files are the source of truth. The request/response shapes are defined once and compiled into TypeScript types that both the caller and handler must satisfy at compile time. HTTP JSON contracts have no such guarantee — a response field can be removed without a compile error.
- Binary serialisation. Protobuf is significantly smaller on the wire than JSON for the same payload. In a system where Giveaway calls Giftcard for every prize allocation, escrow creation, escrow refund, and card availability query, the aggregate throughput difference is meaningful.
- Bidirectional calling. Giveaway calls Giftcard AND Giftcard calls Giveaway. With REST, this would require each service to know the other’s HTTP URL and handle auth on both ends. With gRPC over an internal Docker network, there’s no URL, no auth header — just a typed method call over TCP.
- Every gRPC call is persisted through Bull — not just retried in memory. A `createQueuedGrpcService` Proxy intercepts every gRPC method call before it reaches the wire. Instead of calling the gRPC stub directly, it serialises the service name, method name, and request payload into a `GRPC_CALL` Bull job and enqueues it. The Job Processor picks the job up and executes the real stub call. The caller awaits `job.finished()` with a deadline timeout:
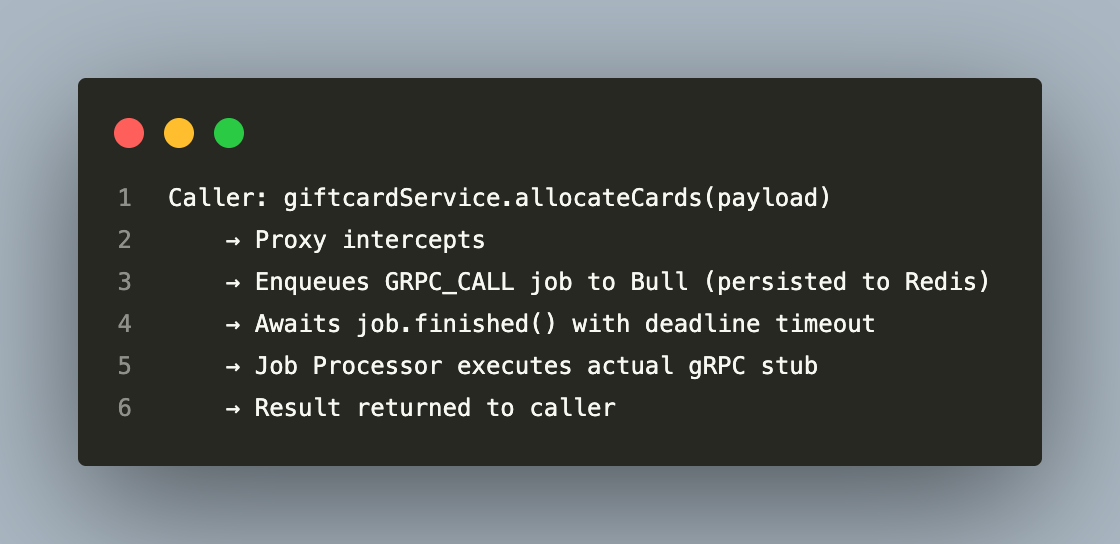
From the caller's perspective this is synchronous — it receives a response or a timeout. But the transport goes through Redis, which means the call state survives an API process restart (the job is still in Redis), and Bull's retry policy handles execution failures at the worker level. The gRPC channel also carries its own keepalive and retry configuration for transient wire-level issues:
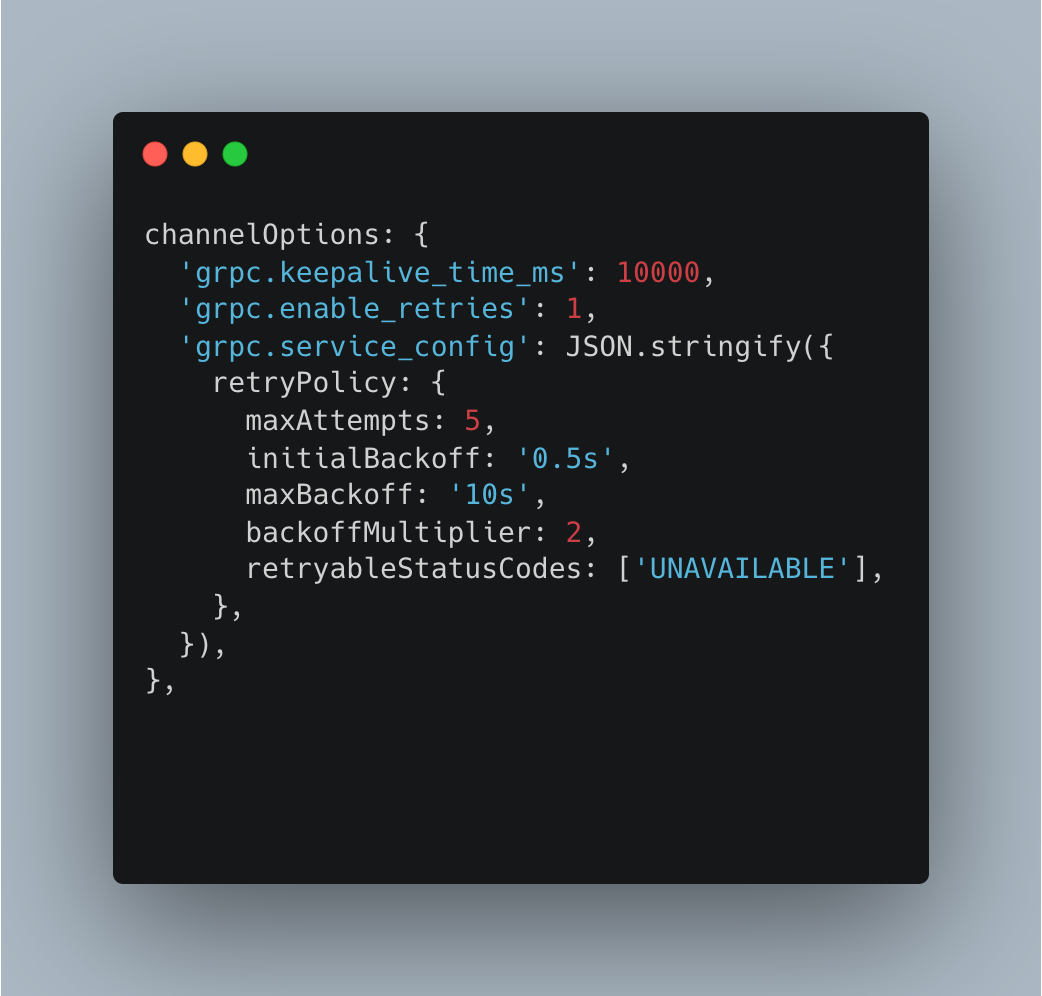
The Circuit Breaker
The circuit breaker sits at the proxy level — before any job is enqueued — and wraps all outgoing gRPC calls:
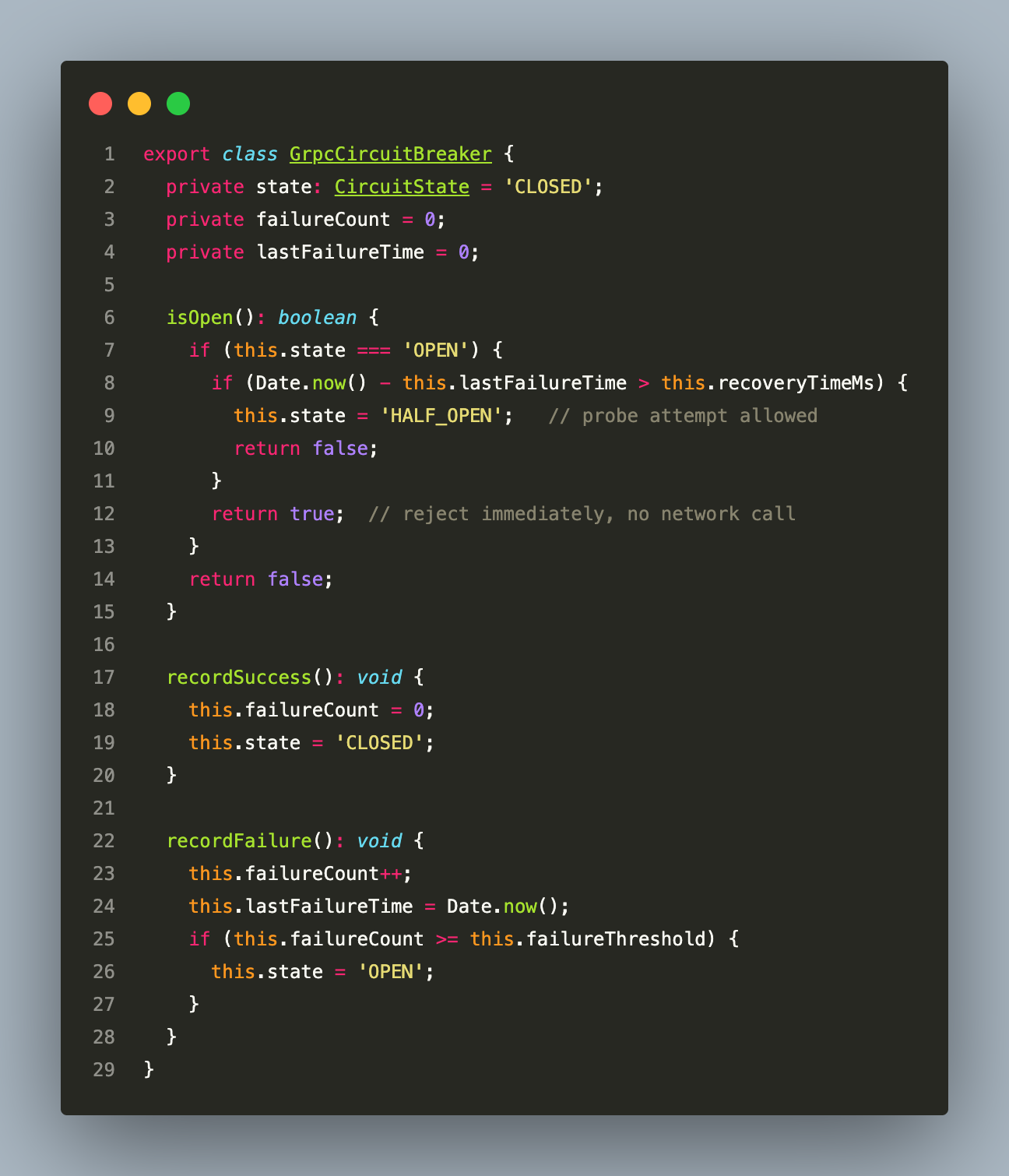
The circuit breaker has three states:
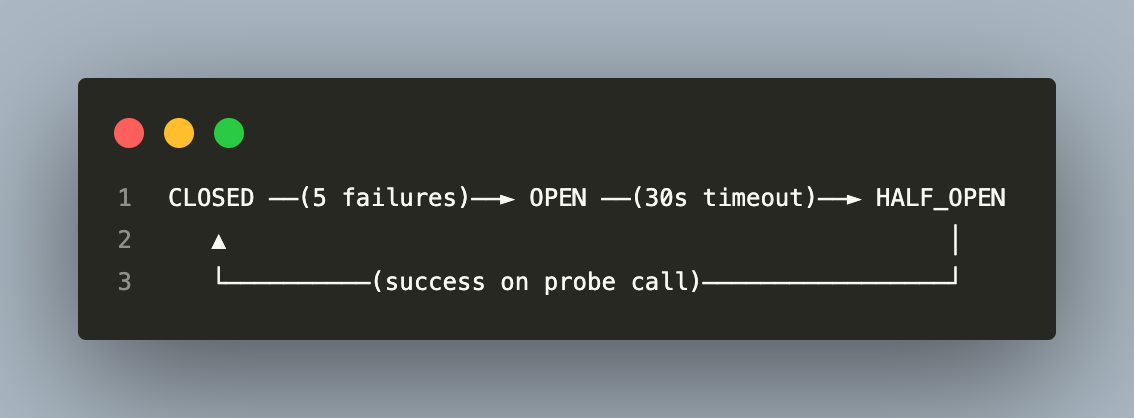
When the Giftcard API is consistently unavailable, the circuit opens after 5 consecutive failures. For the next 30 seconds, all calls to that service are rejected immediately — before any job is enqueued — preventing the Bull queue from filling with `GRPC_CALL` jobs that will all fail on execution. After 30 seconds, one probe is allowed through. On success, the circuit resets to closed.
Proto Contract Example
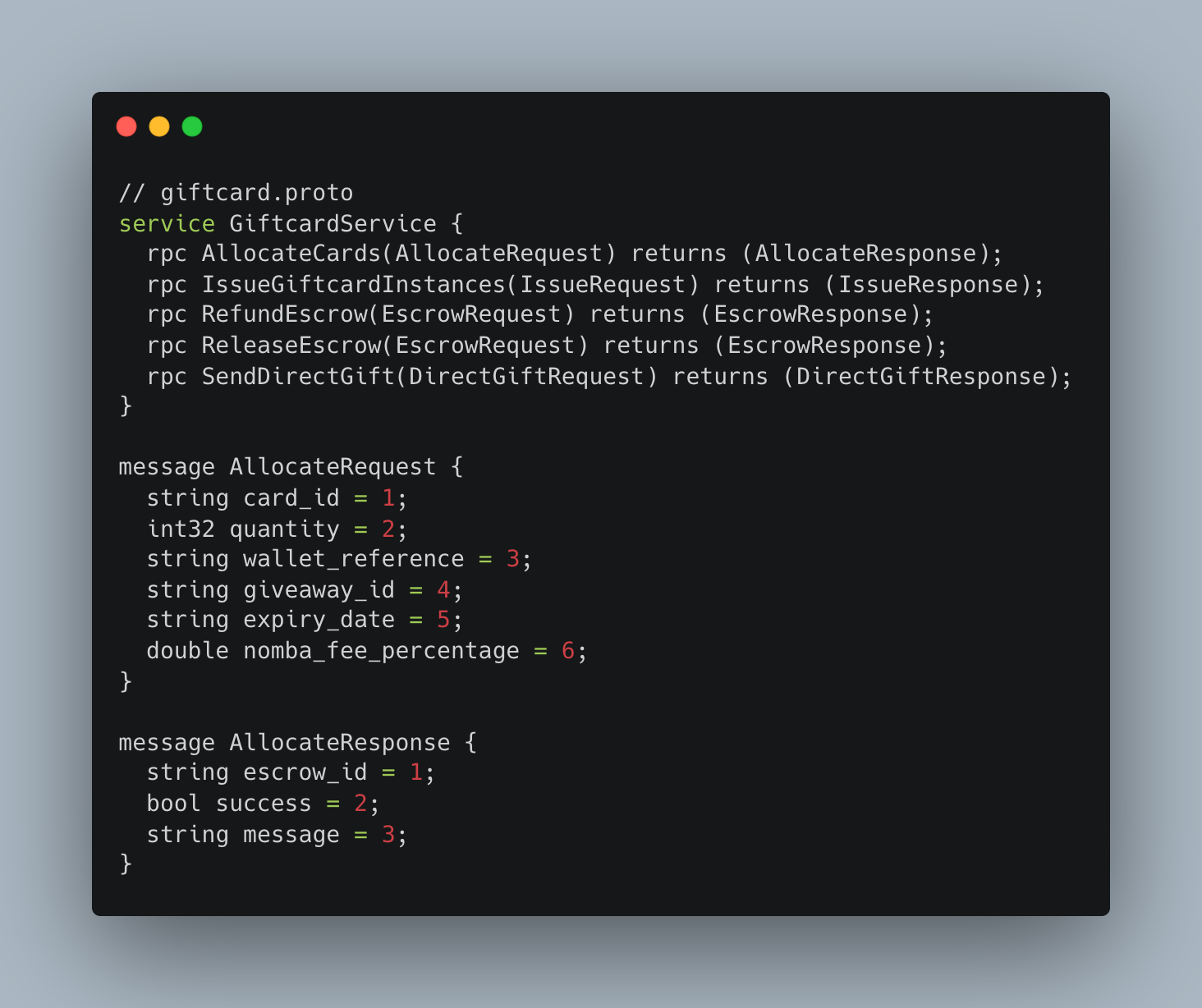
The corresponding TypeScript contract in the shared library:
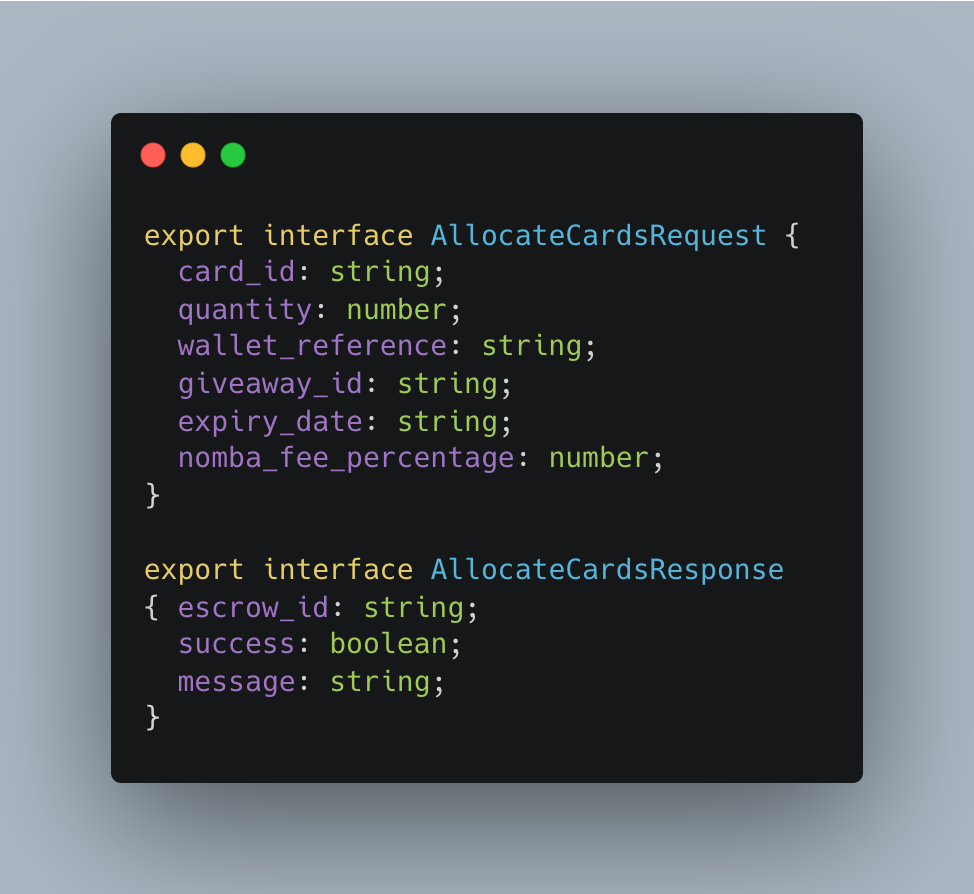
Both the gRPC handler in Giftcard and the gRPC client call in Giveaway reference these exact types. Changing a field name in the proto requires updating the contract file, which breaks both sides at compile time.
6. Redis — Four Roles in One Instance
Redis in this system is not just a cache. It serves four fundamentally different functions, each essential to the system’s correctness and performance.
6.1 Bull Queue Backend
All six job queues (EMAIL, SOCIAL_VERIFICATION, NOTIFICATIONS, ANALYTICS, EVENT_PROCESSING, WEBSOCKET) are backed by Redis via Bull. Bull uses Redis lists, sorted sets, and hash maps to track job state through the full lifecycle: waiting → active → completed/failed.
Redis persistence is enabled with --appendonly yes (AOF mode), meaning queued jobs survive a Redis restart. This is not optional — a restart without persistence would drop queued emails, pending event finalisations, or unprocessed social verifications.
6.2 Socket.IO Adapter (Multi-Process Room Synchronisation)
The WebSocket gateway runs in a separate process from the API services. The system needs any process to be able to emit to a Socket.IO room regardless of which process the client connected to:
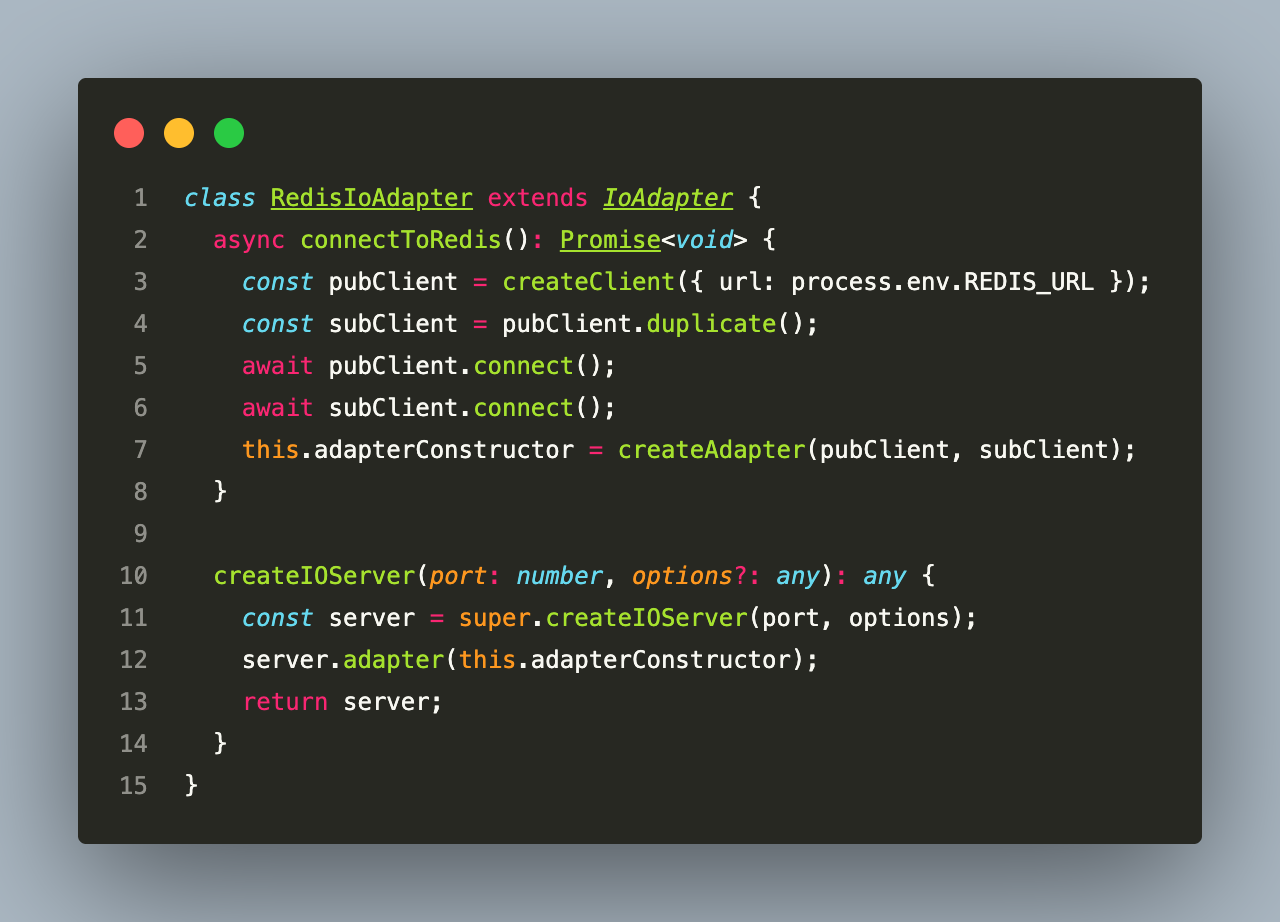
The Socket.IO Redis adapter uses Redis pub/sub to forward room events across all gateway instances. When the Job Processor emits giveaway.winner to room event:EVENT_01ARZ..., that message is published on a Redis channel, and every gateway instance subscribed to that channel propagates it to their connected clients. A client connected to gateway instance 1 receives a message emitted by gateway instance 2.
This is the foundation that makes horizontal scaling of the WebSocket layer possible without any code changes.
6.3 TTL-Based Application Cache
A CacheService sits on top of a RedisService and provides a read-through cache via getOrSet:
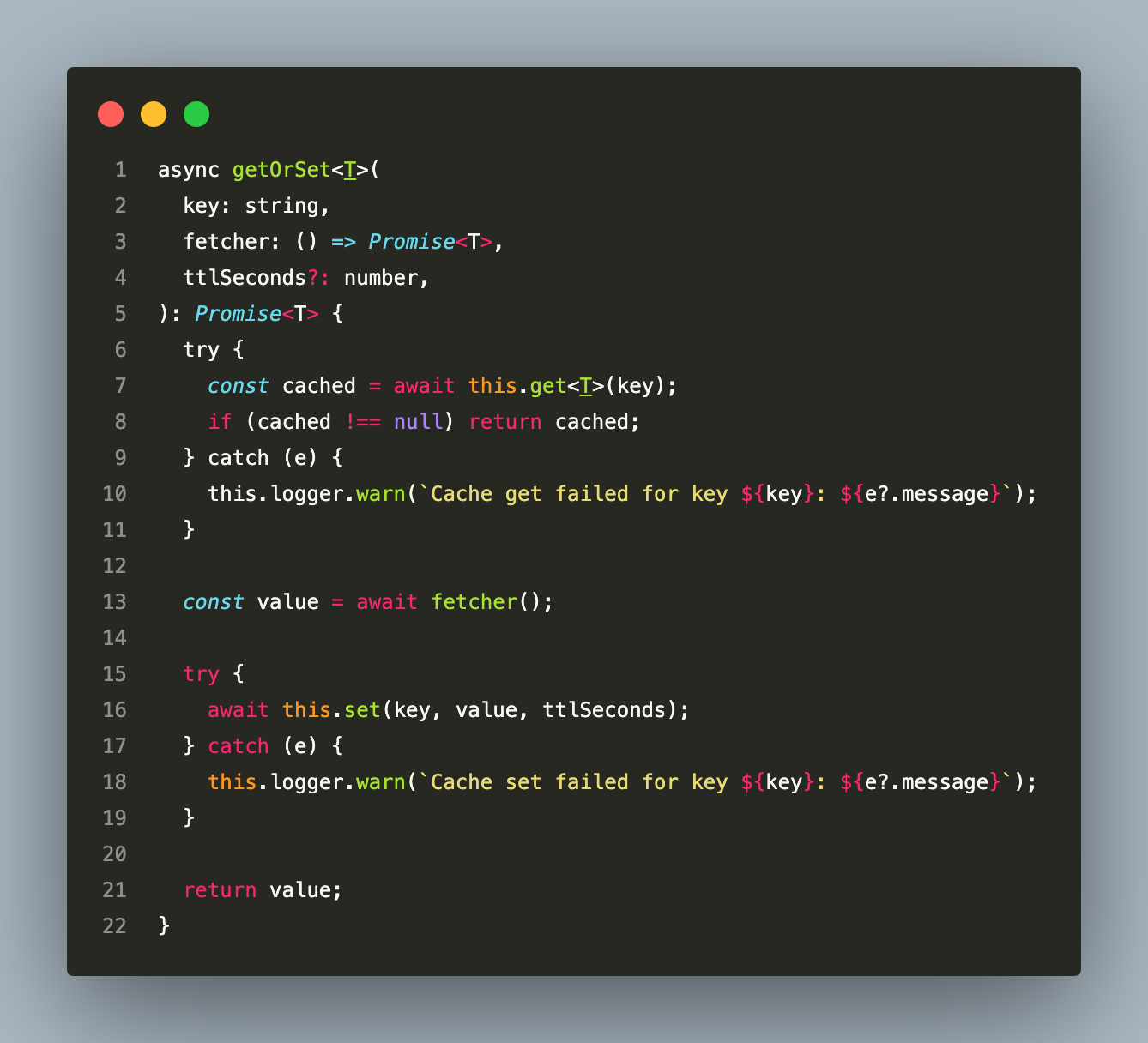
The try/catch around both the get and set is deliberate. If Redis is temporarily unavailable, the cache degrades gracefully to always calling the database — it does not throw a 500 to the client.
Cache keys are constructed with a deterministic builder:
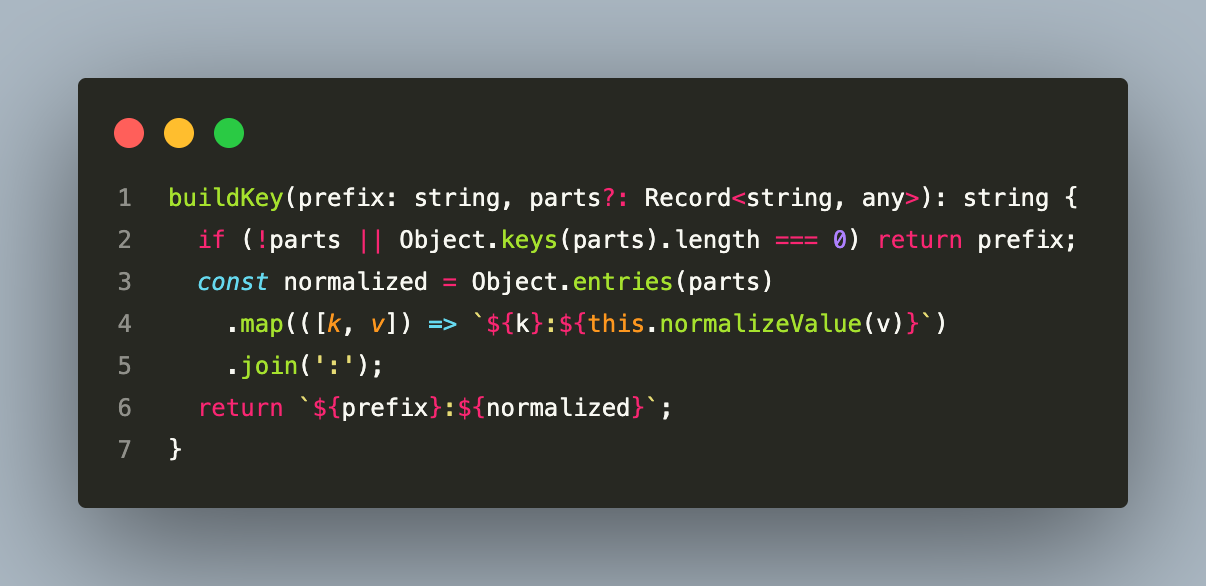
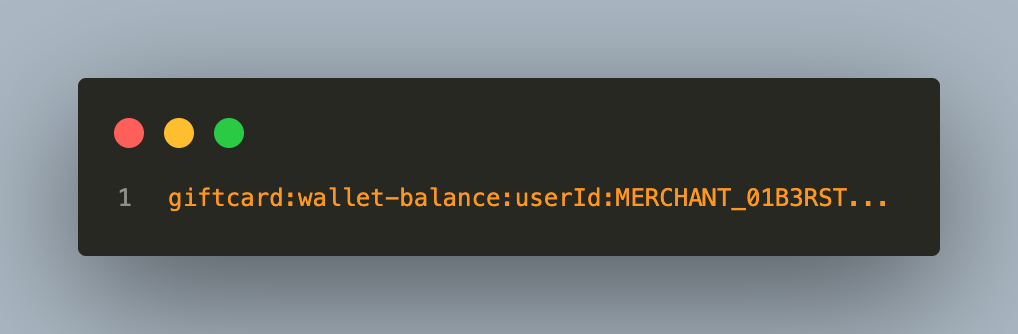
A merchant wallet balance cache key looks like:
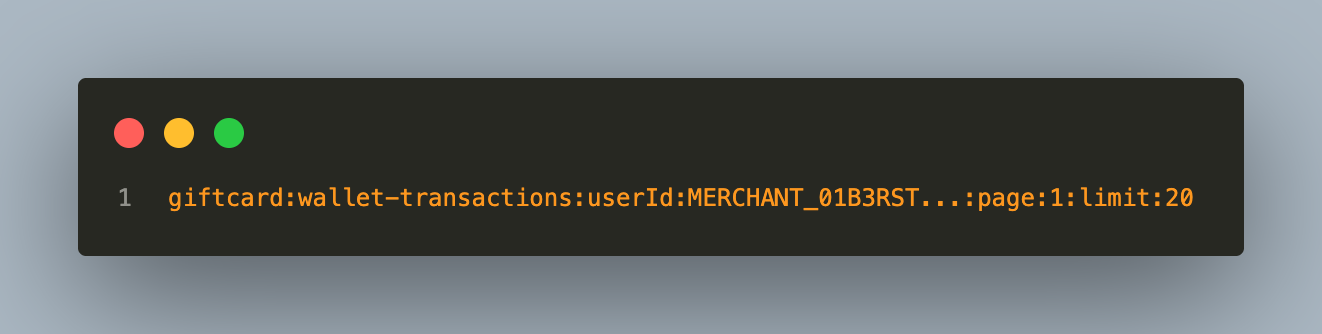
A paginated transaction list:
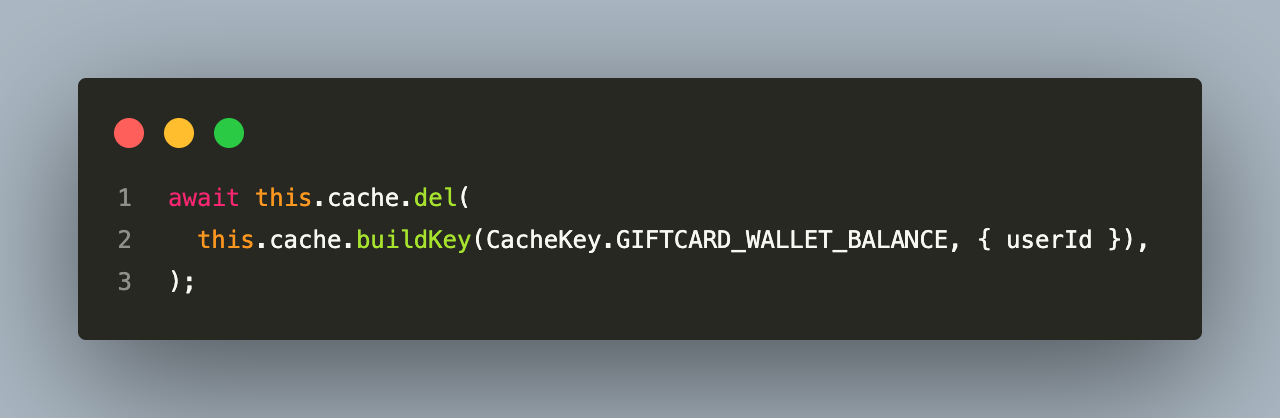
The invalidation strategy distinguishes two categories:
- Point invalidation:
- Prefix invalidation:
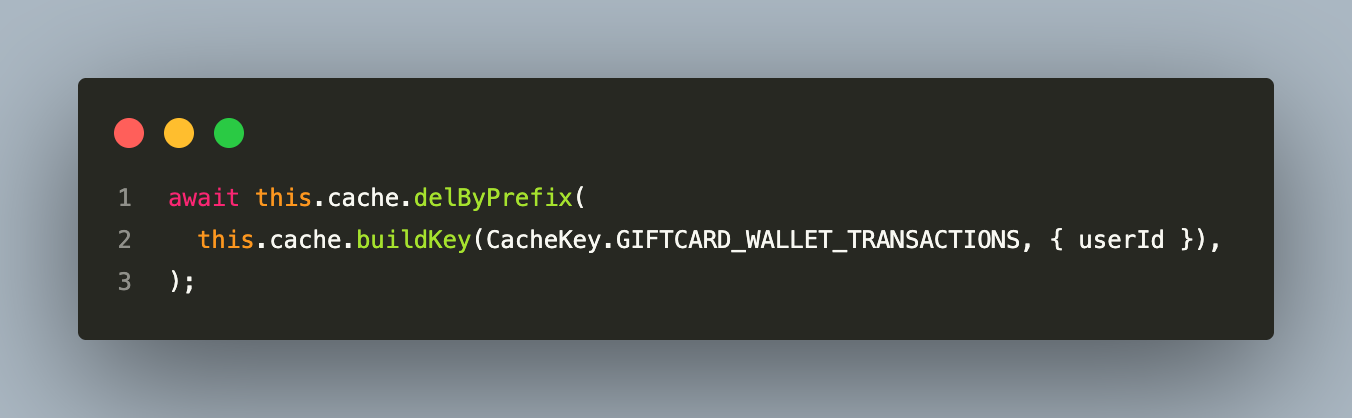
delByPrefix appends :* to the prefix and uses Redis SCAN + DEL to remove all matching keys. The critical distinction: a bare key (no additional segments) must use del, not delByPrefix, because delByPrefix only matches keys with at least one more segment after the prefix.
Analytics caches (metrics, revenue breakdowns, dashboard charts) are TTL-only — no active invalidation. These aggregates are written from dozens of paths (every topup, every event, every redemption). Invalidating after every write would eliminate the cache benefit entirely. One-hour staleness is acceptable for admin dashboards; they are not operational dashboards.
6.4 Atomic Counters for Concurrency Control
The most interesting Redis usage is the atomic counter that powers the real-time winner selection algorithm. During a live event, multiple participants submit attempts simultaneously. The system needs to award exactly N prizes without over-awarding — even under concurrent load.
The solution is a Lua script executed atomically inside Redis:
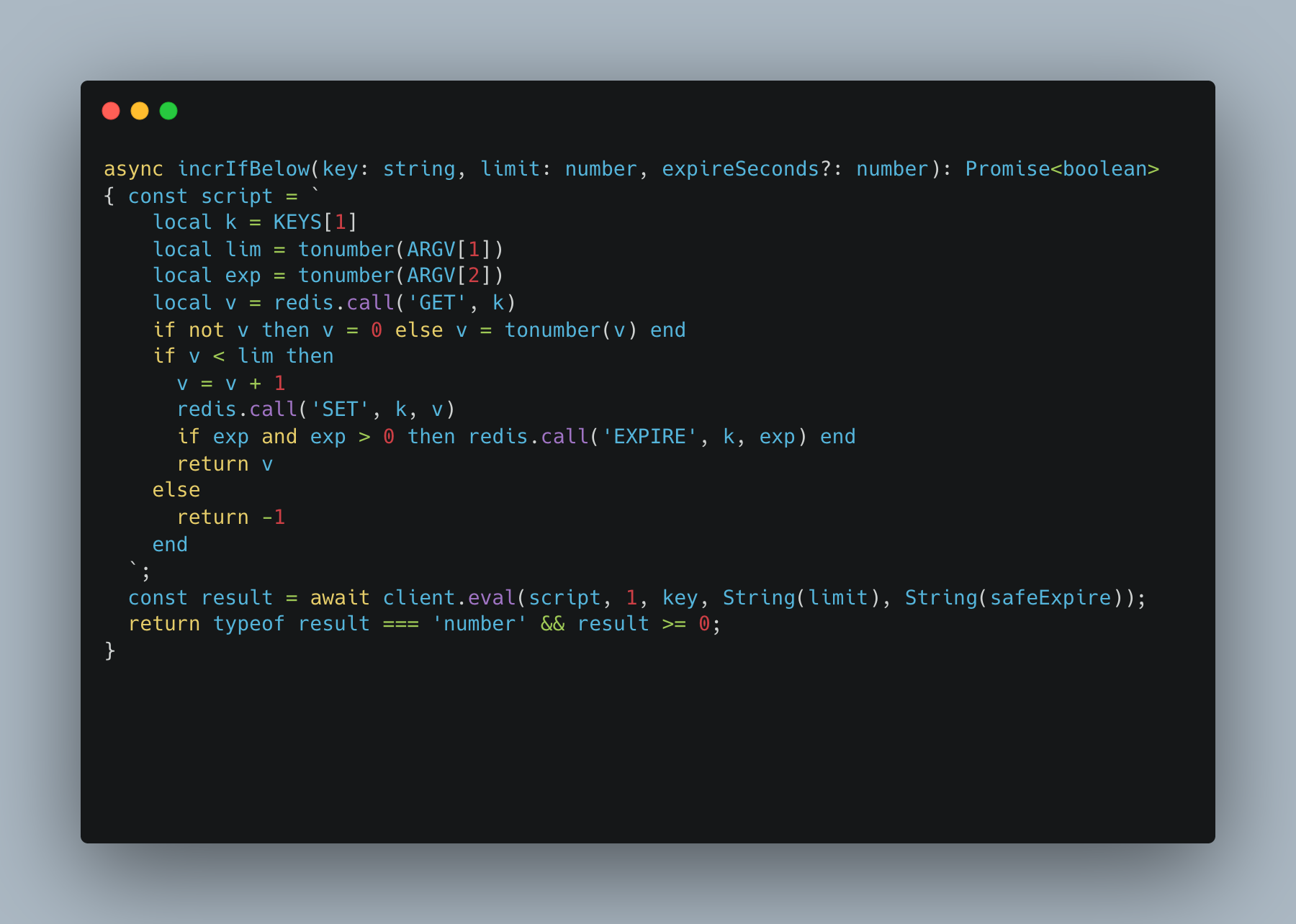
The winner selection algorithm:
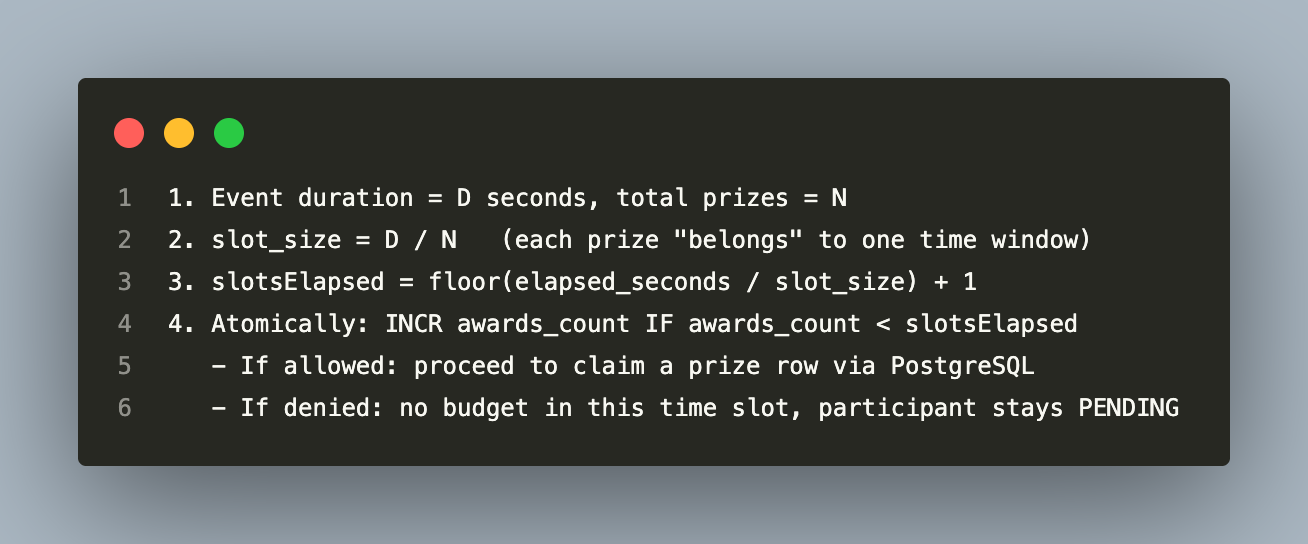
The Lua script is atomic at the Redis level — no two requests can race on the counter. A PostgreSQL `SELECT FOR UPDATE SKIP LOCKED` on the prize row is the final safety net — it ensures exactly one participant claims each physical row, even if two participants simultaneously pass the Redis gate.
The Redis key has a TTL equal to `event_duration + 60 seconds`. When the event ends, the key expires automatically with no cleanup job needed.
6.5 Why One Redis Instance Handles All Four Roles Reliably
The natural question when seeing Redis used for four concurrent purposes is whether those roles compete with each other and whether a single instance is a reliability risk.
The four roles use completely separate data structures.** Bull occupies Redis lists, sorted sets, and hashes under the `bull:` key prefix. Socket.IO uses pub/sub channels, which are an entirely separate Redis mechanism. Cache entries are string keys with TTLs. Atomic counters are individual string keys operated on by Lua scripts. From Redis's internal perspective these are four isolated namespaces sharing one event loop, not four workloads fighting over shared state.
Redis is single-threaded for command execution.
Every command — a Bull job enqueue, a Socket.IO broadcast, a cache GET, a Lua counter increment — is processed in strict sequence on one thread. This is what makes the Lua atomic counter correct: no two commands can interleave, so there are no race conditions and no locking overhead. The tradeoff is that one slow command can delay others, but the commands used here (list pushes, string GETs, pub/sub publishes) are all sub-millisecond operations.
The actual command throughput at this scale is well within Redis's ceiling.
A single Redis instance handles 100,000+ simple operations per second on modest hardware. During a peak live event — Bull queues loaded, Socket.IO adapters active, cache warm, prize counters running — the realistic Redis command rate is a few thousand per second at most. There is substantial headroom before throughput becomes a concern.
Memory is the primary constraint.
Redis keeps everything in RAM. At idle the instance uses 40–80 MB. At sustained peak load across all four roles it is realistically 200–400 MB. The 16 GB VPS has significant headroom. Setting `maxmemory-policy allkeys-lru` ensures that if memory pressure does grow, Redis evicts the least recently used cache keys — not Bull job data, which is consumed by active workers and not eligible for passive eviction.
The real risk is single point of failure, not concurrent load
One Redis instance means one crash point. AOF persistence (`--appendonly yes`) is enabled, so queued Bull jobs survive a process crash and come back when Redis restarts. Socket.IO room memberships are ephemeral — clients reconnect automatically on gateway restart. Cache misses fall through to the database gracefully via the `getOrSet` pattern's try/catch design. The durability concern is genuinely about Bull jobs, and AOF addresses it.
Redis Sentinel (automatic failover with a standby replica) or Redis Cluster (horizontal sharding) would eliminate the single point of failure. Both add operational complexity that is not justified at the current scale. The scaling section covers when and how to migrate Redis to a dedicated VPS — which is the step that precedes any HA configuration.
7. The Job Processor — Worker / Gateway Split
The Job Processor is a single NestJS binary that boots in one of three modes controlled by JOB_MODE:
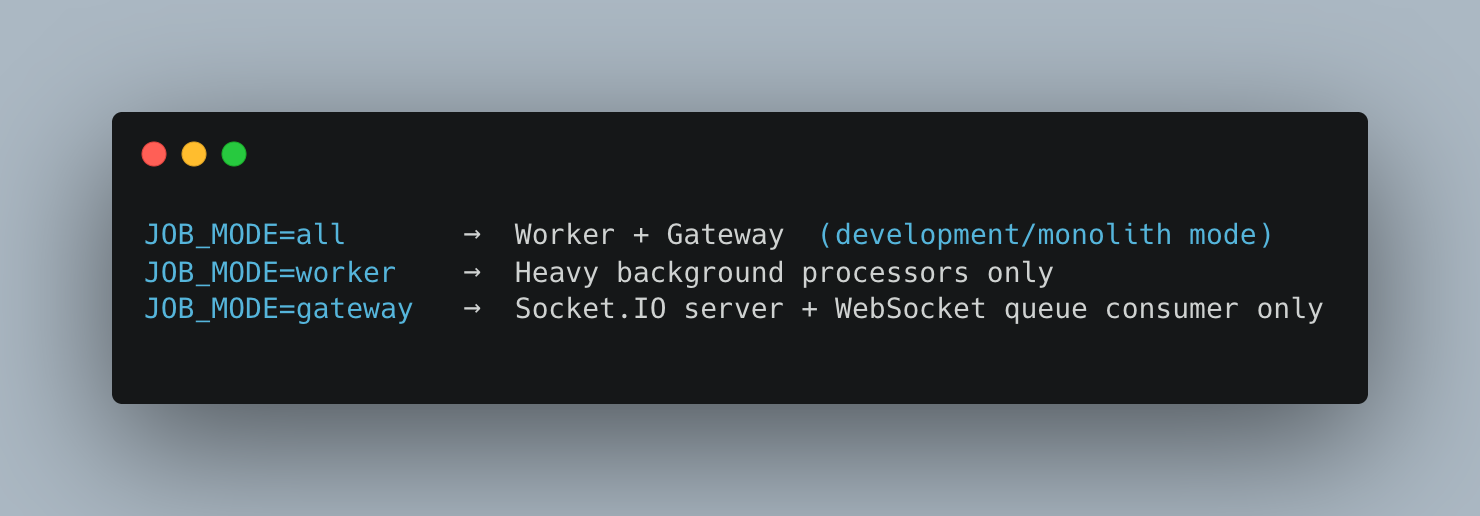
Why split them?
They scale on completely different axes:
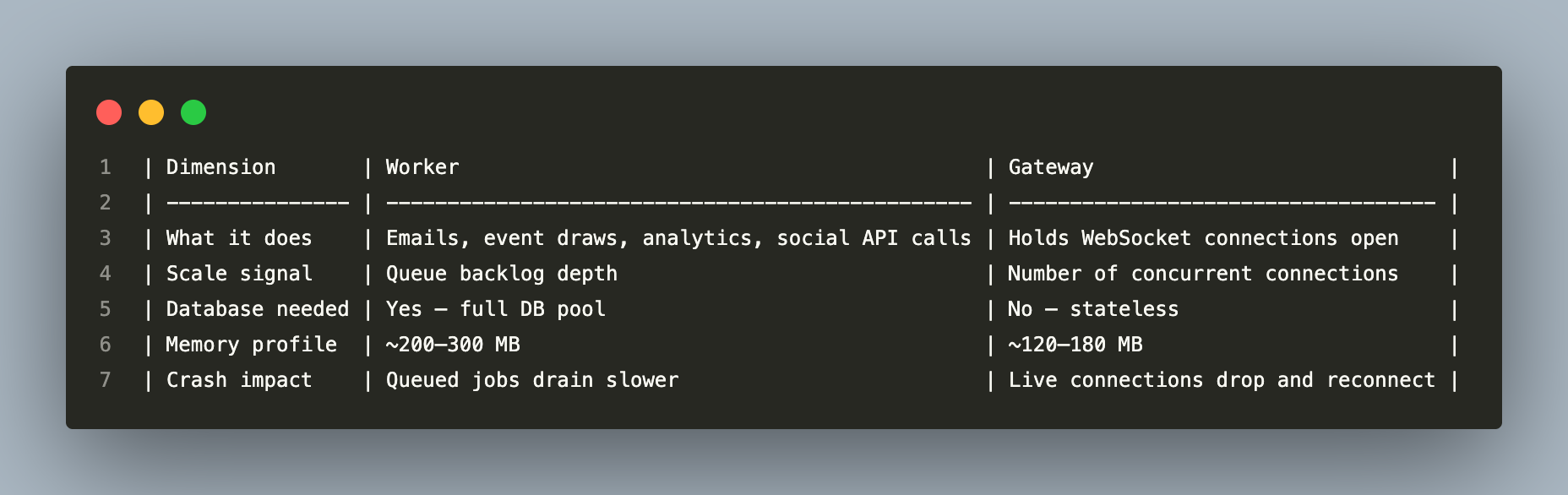
If the worker crashes, queued jobs sit in Redis until the worker restarts — no data is lost because Bull persists job state in Redis. If the gateway crashes, connected clients disconnect but reconnect via Socket.IO’s built-in reconnection logic. These are independent failure modes and independent scaling axes.
The WebSocket Emit Path
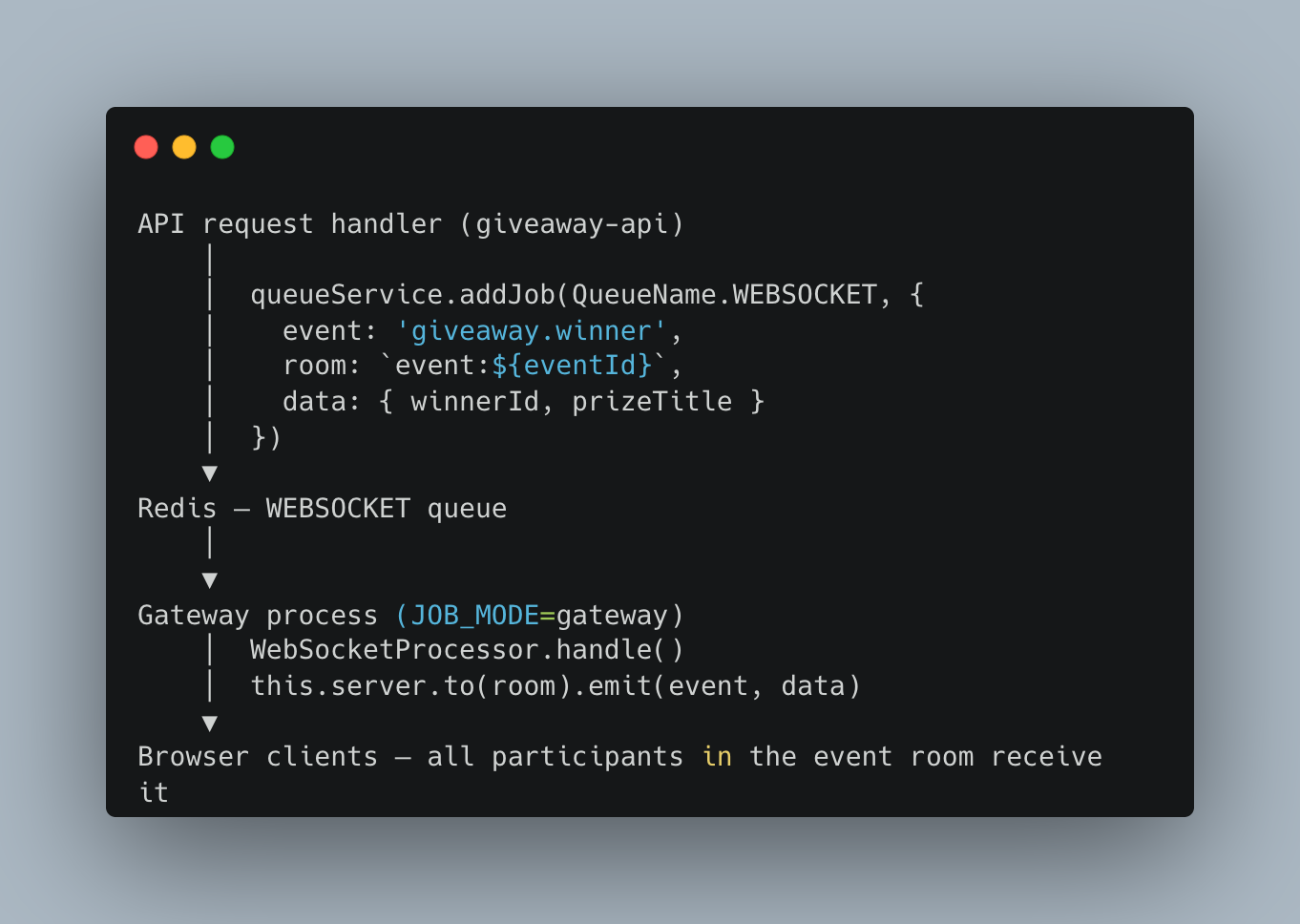
The API process never touches Socket.IO directly. This design prevents a scenario where a long-running WebSocket emit blocks an HTTP request handler. Everything is mediated through the Bull queue.
Scaling Workers Without Kubernetes
Because container_name is intentionally absent from the scalable containers, Docker Compose can scale them horizontally with a single command:
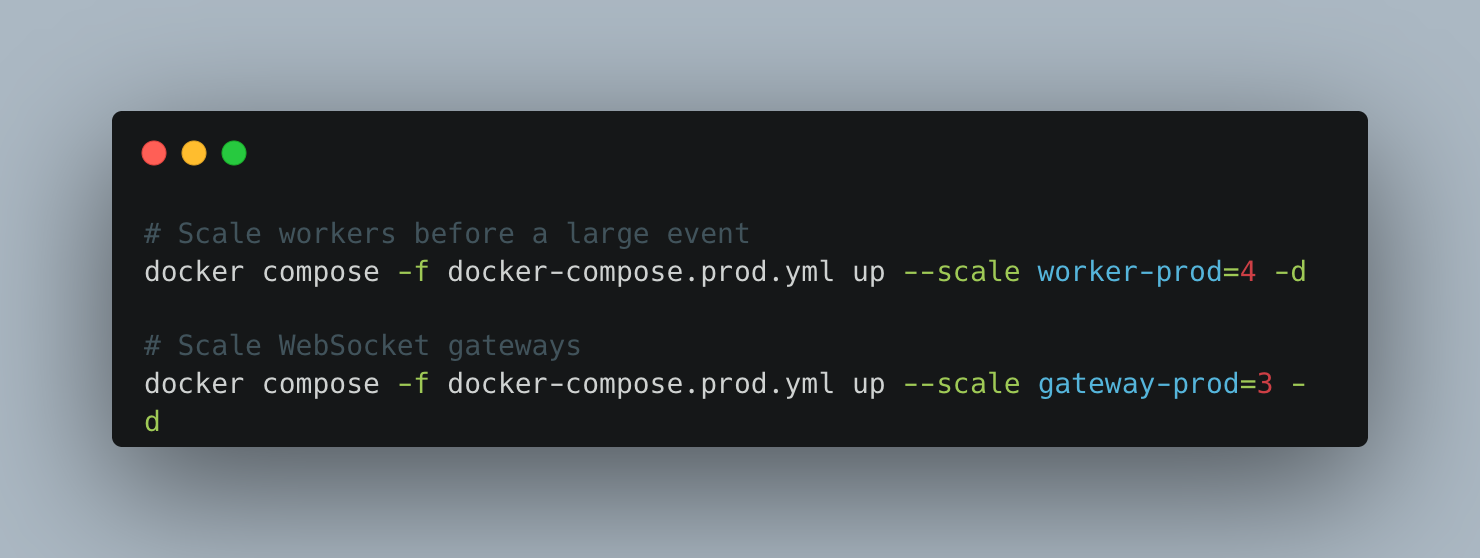
Bull automatically distributes jobs across all worker instances — no configuration change needed. The Redis adapter keeps Socket.IO rooms synchronised across all gateway instances automatically.
8. The Escrow State Machine and Financial Architecture
This is where the system design gets most interesting. The platform handles real money, which means every financial operation must be atomic, idempotent, and auditable.
The Four Payment Sub-Accounts
The payment provider supports internal transfers between sub-accounts with no fees and near-instant settlement. The system maintains four accounts:
MAIN account ← User topups land here via virtual bank account
ESCROW account ← Reserved prize funds (DB-tracked, Nomba account as backing)
WITHDRAWAL account ← Merchant net payout destination
FEE account ← Platform service fee collection
Escrow State Machine
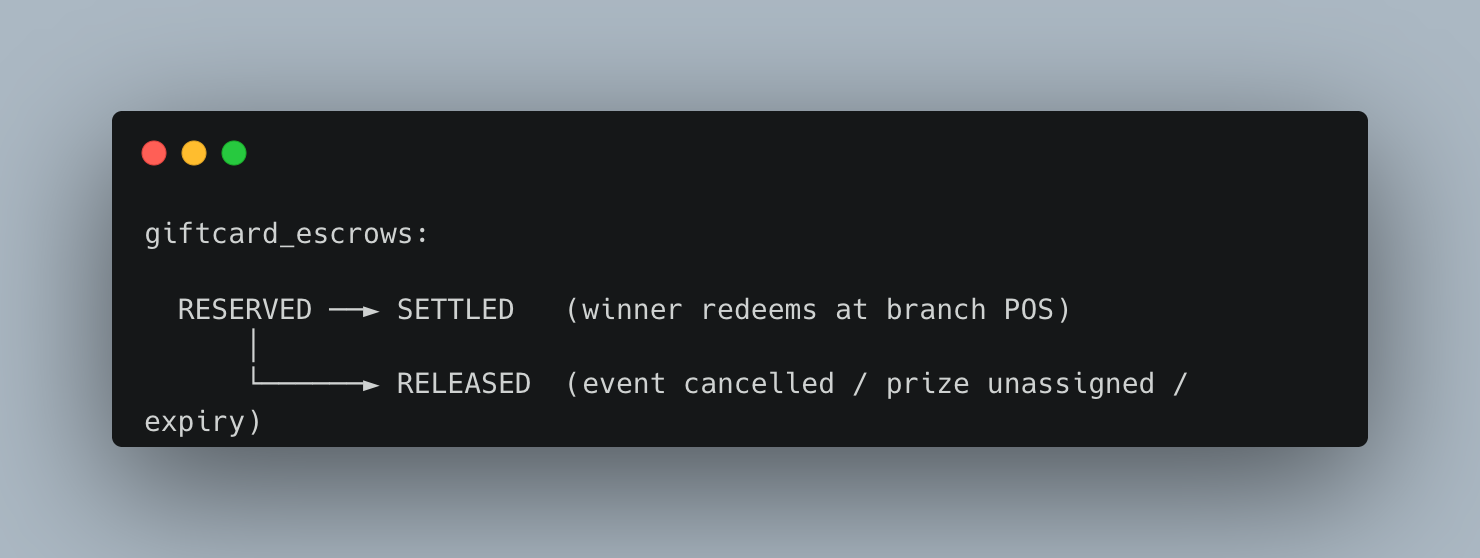
State transitions are irreversible. Once an escrow moves to SETTLED or RELEASED, it cannot be changed. This is enforced at the code level — the service methods that create these transitions validate the current state before proceeding and throw if the transition is invalid.
The Fee Calculation Problem — Dynamic Payment Fees
One non-obvious complexity: the payment provider charges a variable fee on every deposit to a virtual account. This fee is deducted from the incoming transfer before the platform receives it. The system cannot hardcode a fee rate because the provider adjusts it.
The solution: track the actual fee amount on every topup transaction.
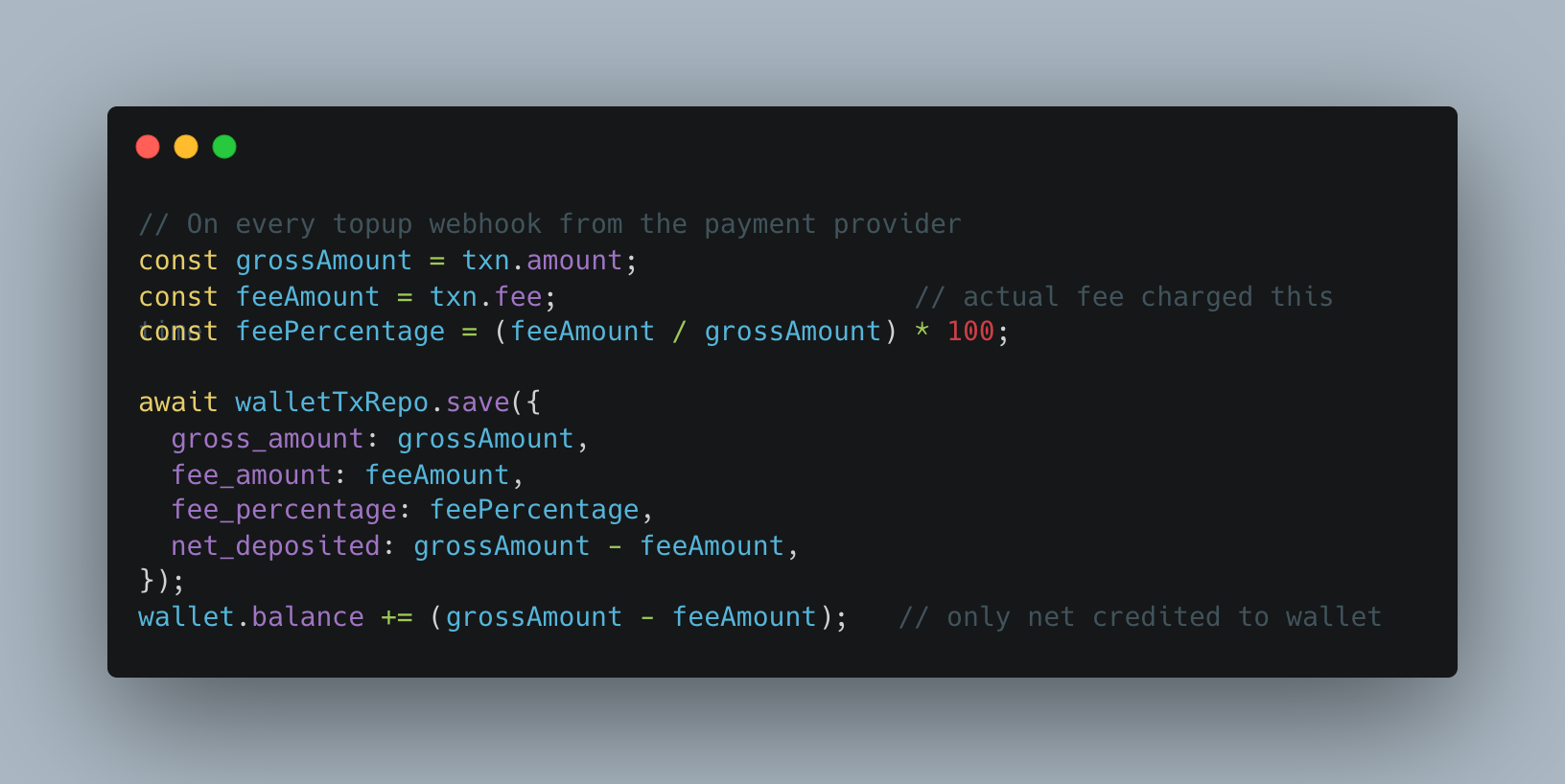
At escrow creation, the system computes a weighted-average fee percentage across all of that wallet’s historical topups:
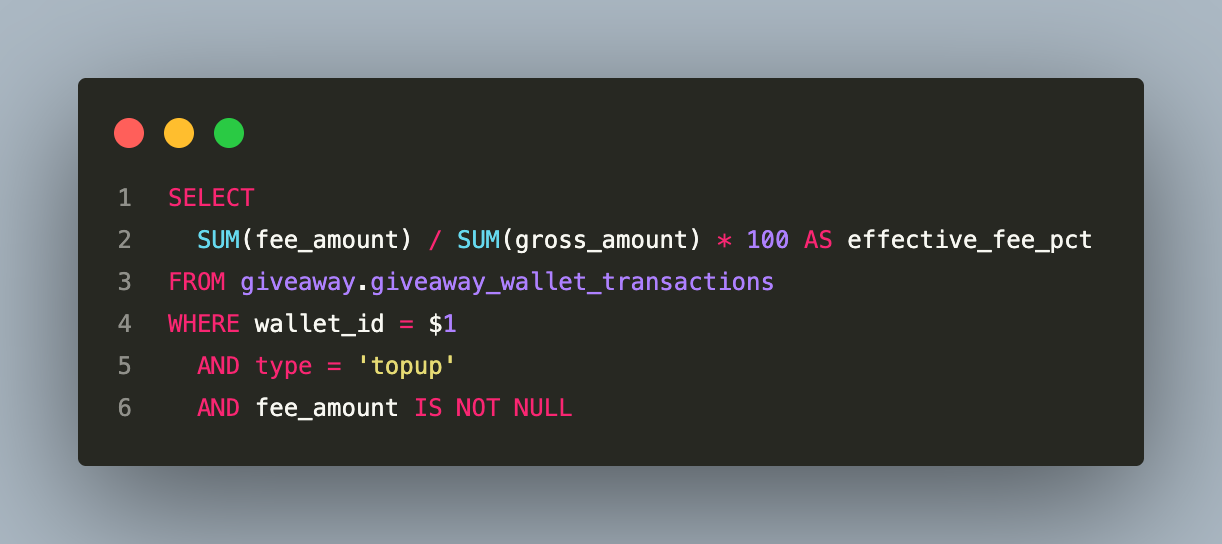
This percentage is stored on the escrow record. At redemption, the settlement calculation strips out the provider’s portion before applying the platform’s service rate:
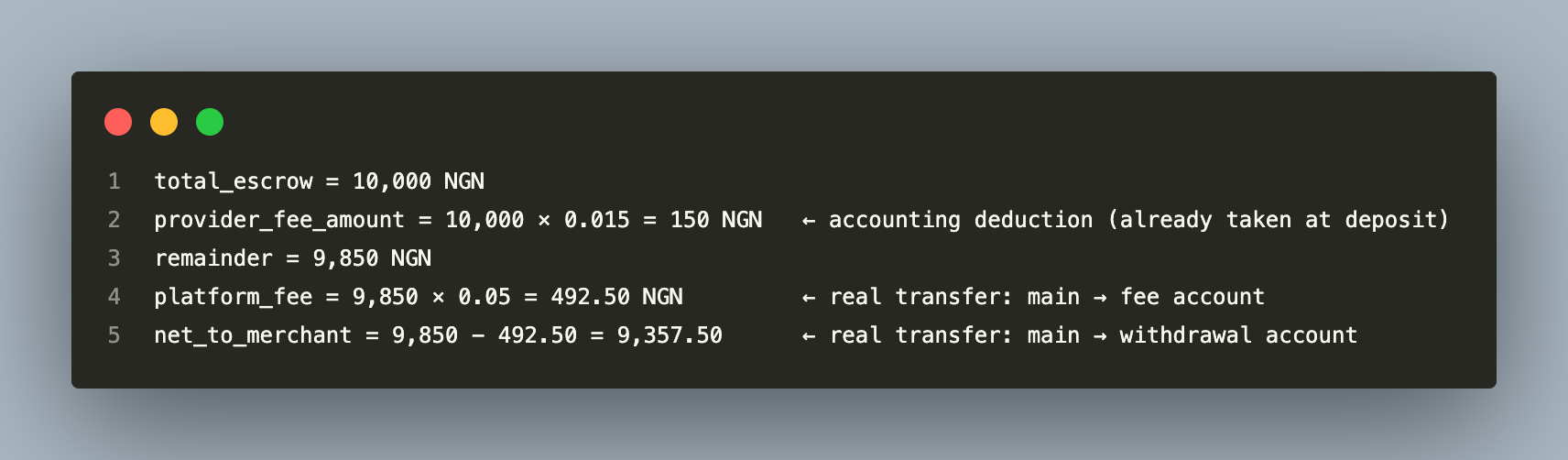
The provider fee is a pure accounting deduction — it is never transferred at settlement because the provider already took it at deposit time. Without tracking it, the platform would charge a service fee on money it never held, creating a systematic double-charge on merchants.
Idempotency on Financial Operations
Every financial operation carries an idempotency key. For topup webhooks:
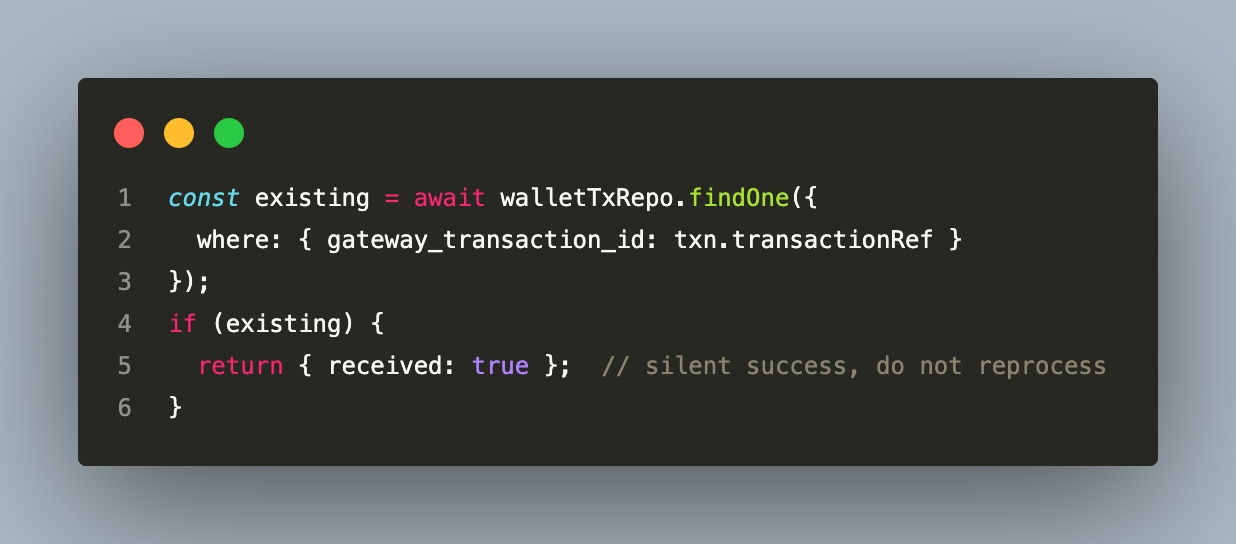
For internal transfers at settlement, the escrow ID is used as the reference prefix: - Settlement leg 1 (net to merchant): {escrowId}-NET - Settlement leg 2 (fee to platform): {escrowId}-FEE
If either transfer is retried, the payment provider recognises the reference and returns success without double-charging.
Transaction Ordering — DB Before External Calls
For direct telecom gifts (airtime/data vending), the Nomba payout_success webhook can arrive before the API handler returns if the vend completes extremely fast. The solution is writing the gift record to the database before the external call:
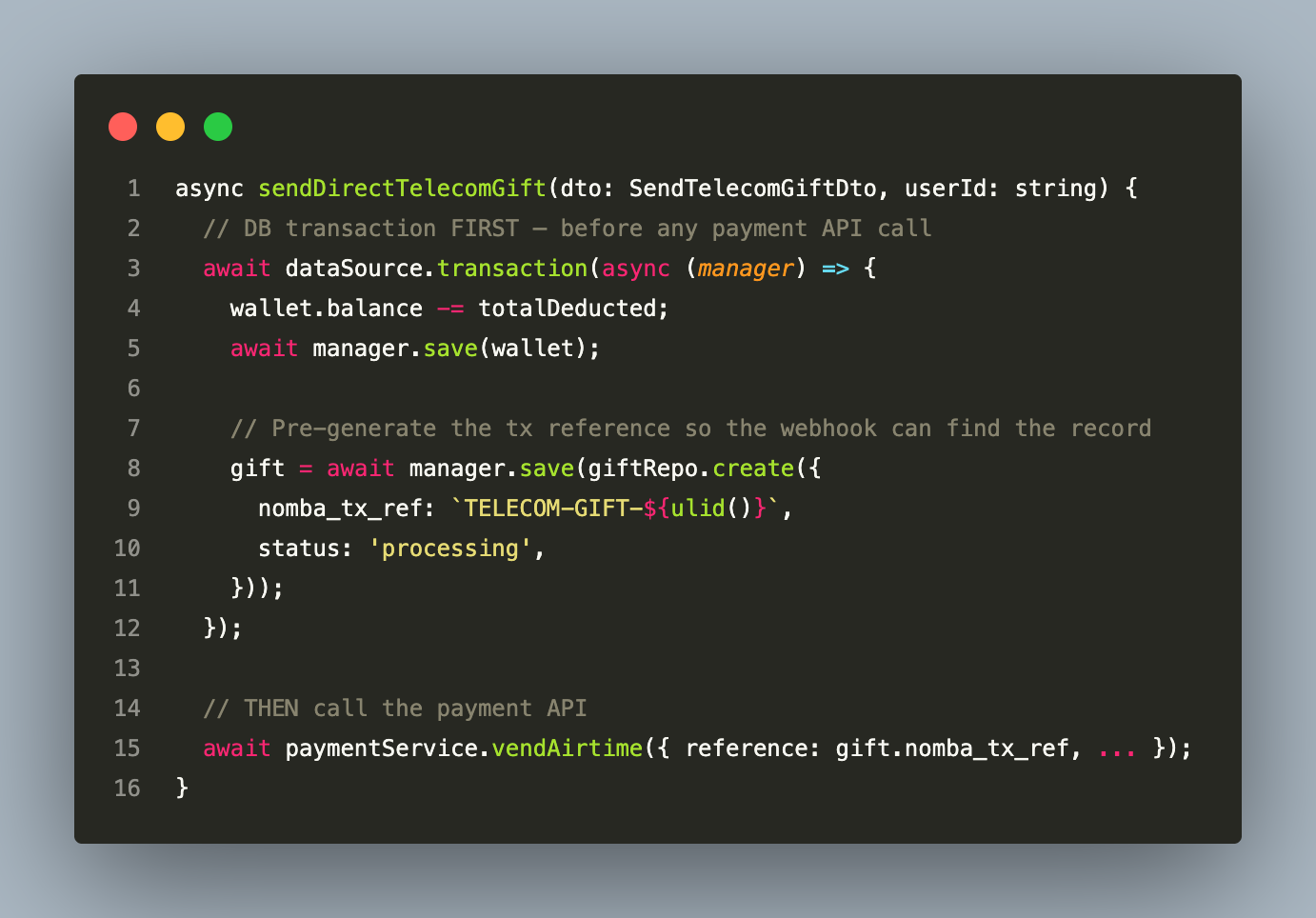
Writing the gift record before the external call means the webhook handler will always find the record to update, regardless of timing. This pattern is applied consistently across all webhook-backed financial operations.
Redemption Settlement — The “Payment Before DB” Exception
Redemption is the one place where payment transfers happen before the DB commit. This is a deliberate, documented exception:
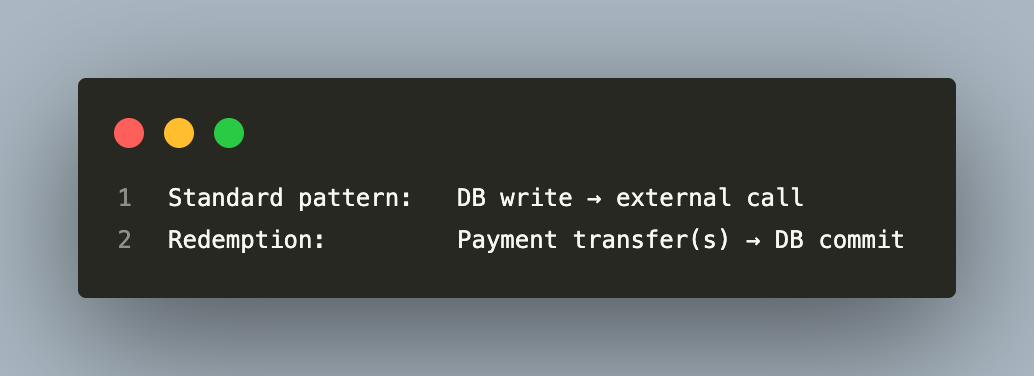
Why?
At redemption, two payment transfers must happen atomically from the caller’s perspective. If the DB were committed first and then a transfer failed, a compensation transaction would be needed to reverse the DB state — complex and error-prone. By running the payments first, a failure on either leg means the DB was never touched, and a retry is safe. Both transfer references are idempotent, so retrying after a partial success is also safe.
9. Authentication Architecture
JWT Strategy
Access tokens are short-lived (default 1 day), refresh tokens long-lived (default 7 days). Both are signed with separate secrets. The payload is minimal — just the user ID, issued-at timestamp, and expiry — to keep the token small and avoid stale data being encoded into it.
Token blacklisting is stored in the auth table as a JSON array. On every authenticated request, the guard checks the token against this array. A separate giftcard-jwt.strategy.ts in the Giftcard API validates the same JWT secret but resolves the user through that service’s schema references, keeping authentication concerns scoped per service.
OAuth Account Linking
A particularly clean flow handles the case where a user who registered with email/password tries to sign in with Google using the same email:
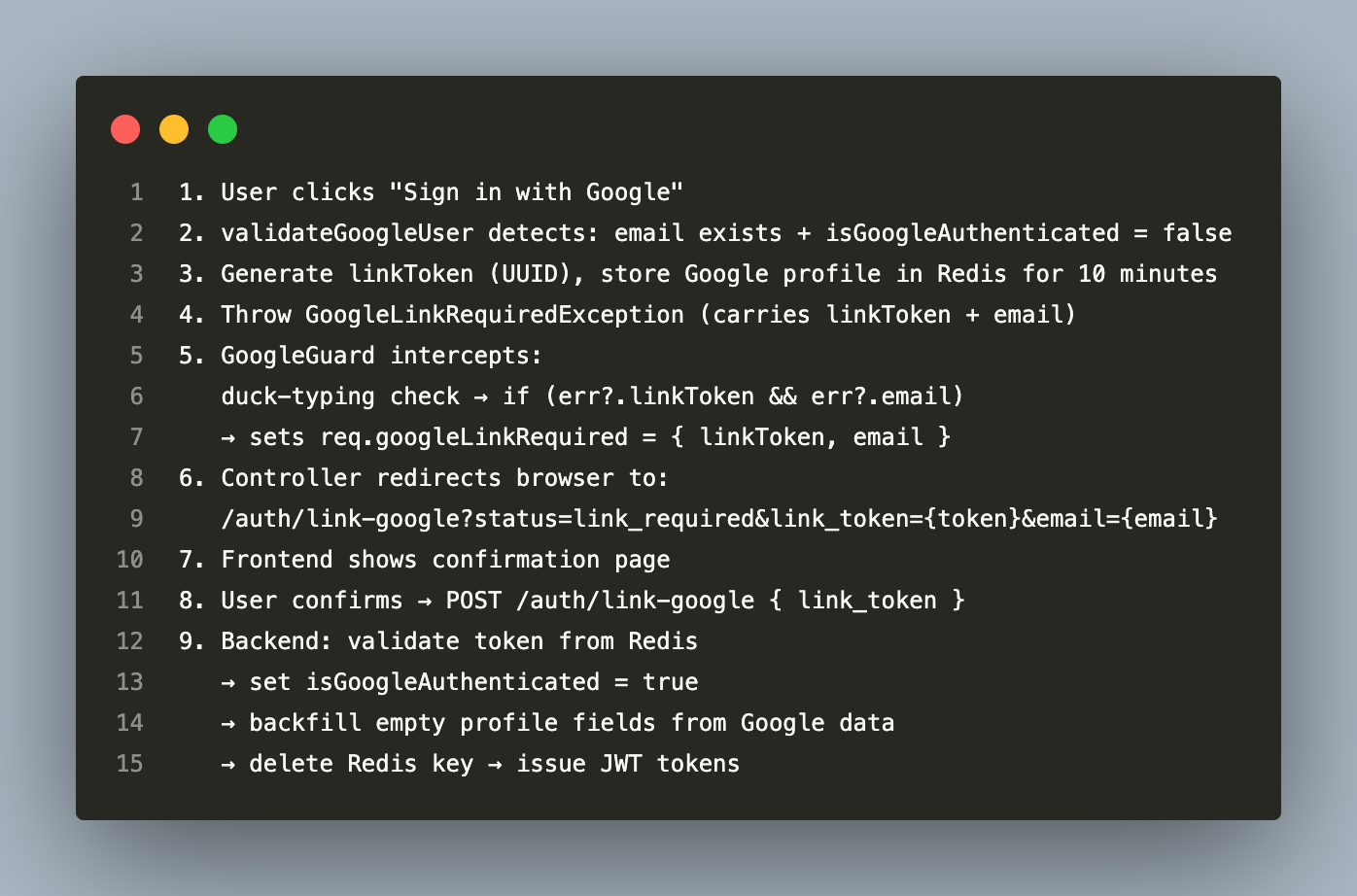
This flow avoids the naive alternative (silently merge accounts without user consent). The 10-minute Redis TTL on the link token prevents long-lived dangling states. The duck-typing check on the exception avoids subclassing the Passport strategy, which keeps the guard reusable.
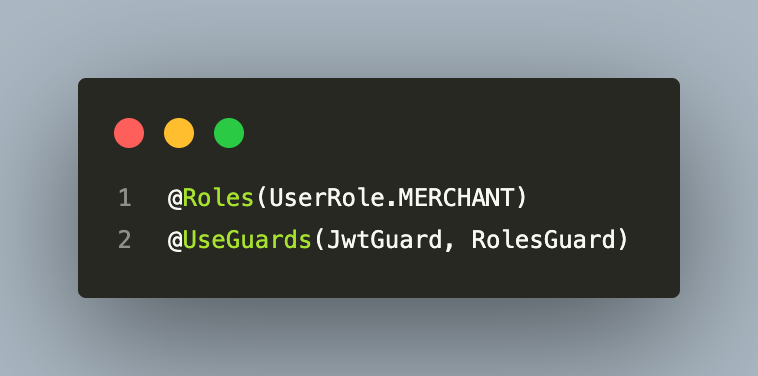
Role and Permission Model
Two access control systems coexist:
Role-based (Giveaway API):
Permission-based (Giftcard API):
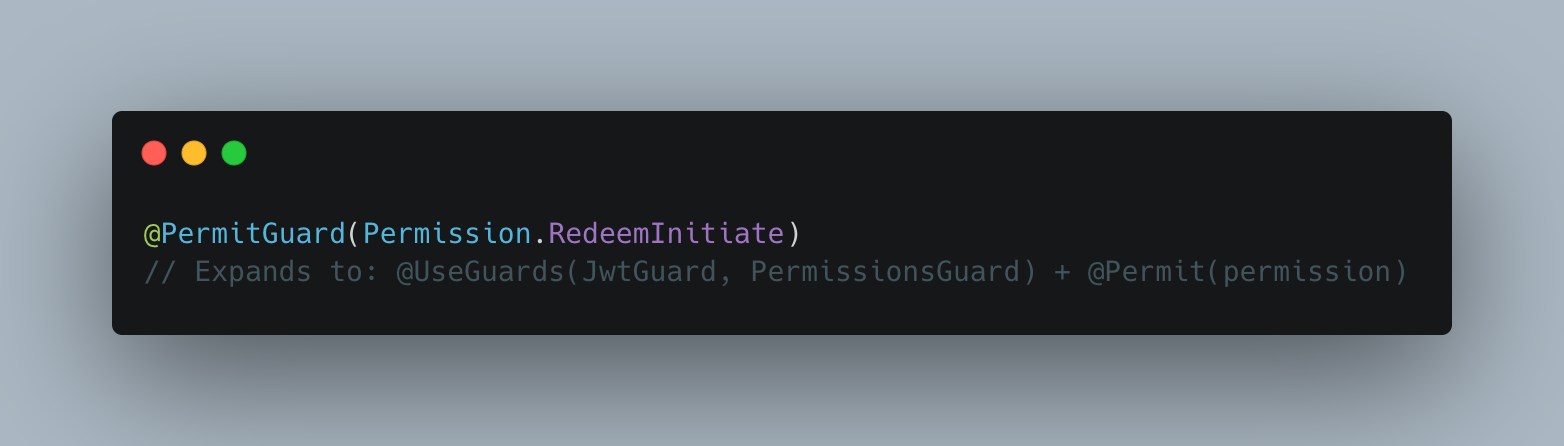
The permission model is more granular — a BranchManager has RedeemInitiate but not WalletsWithdraw, even though both are valid authenticated users. The PermitGuard is a single decorator that wires the JWT guard, the permissions guard, and the Swagger bearer auth documentation in one step, eliminating the repeated three-decorator pattern across all giftcard endpoints.
10. Security Layers — Defence in Depth
The system implements security at four distinct layers, each independent of the others.
Layer 1 — Traefik Rate Limiting
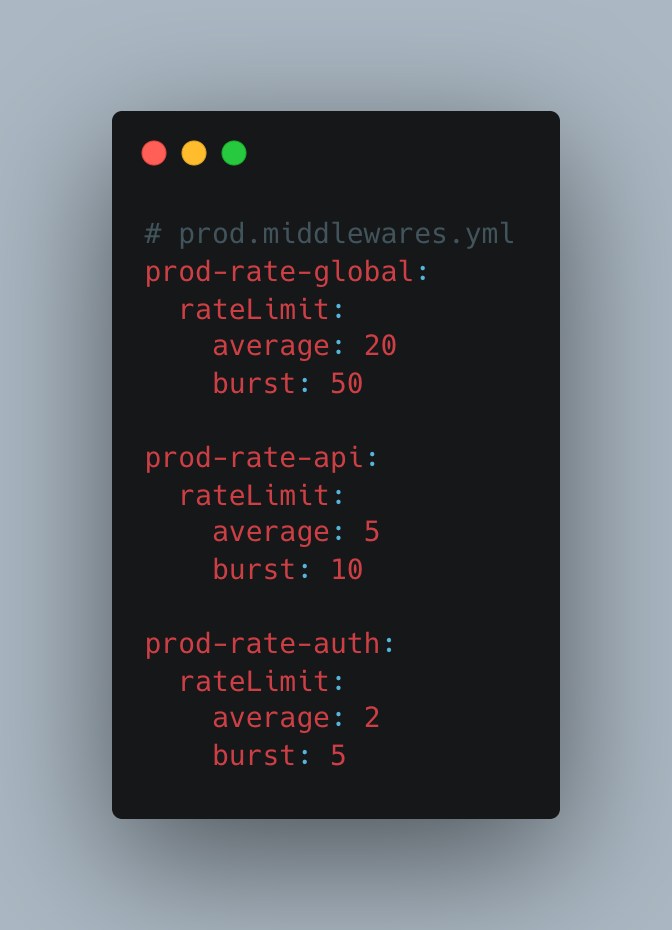
Auth endpoints are rate-limited the most aggressively. The limits are applied per-IP by Traefik before the request ever reaches the application. A credential stuffing attack is denied at the proxy layer, not the application layer — cheaper to reject there.
Layer 2 — Application-Level Abuse Protection
For public endpoints (participant registration, QR scanning) that cannot use JWT authentication, an AbuseInterceptor provides fingerprint-based rate limiting backed by Redis atomic counters:
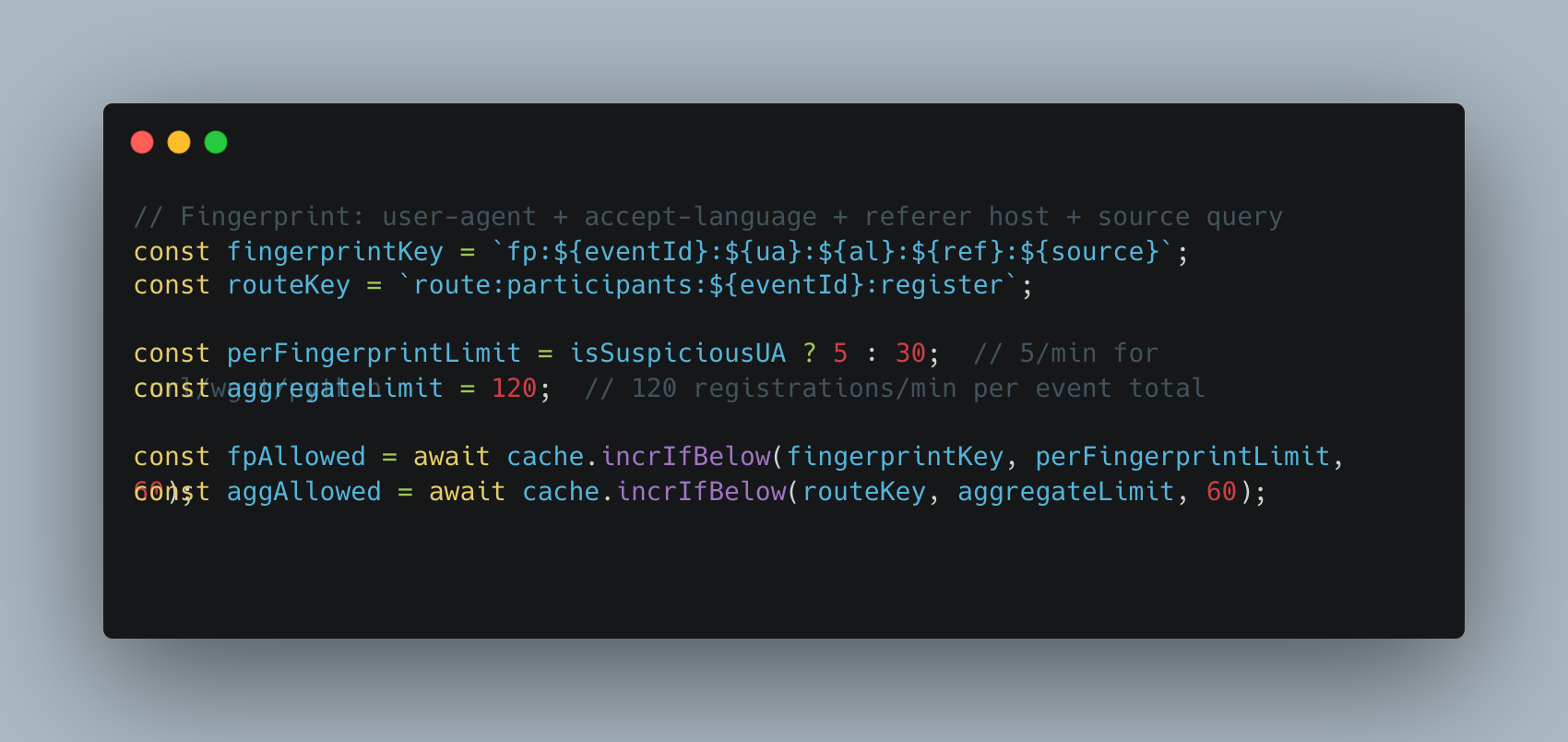
Suspicious user agents (curl, wget, python-requests, Postman, etc.) are capped at 5 requests per minute per fingerprint. The aggregate per-event limit ensures a single event cannot consume disproportionate server capacity even if the fingerprint detection is bypassed.
Layer 3 — Webhook Signature Validation
Every payment webhook is validated before any payload is parsed:
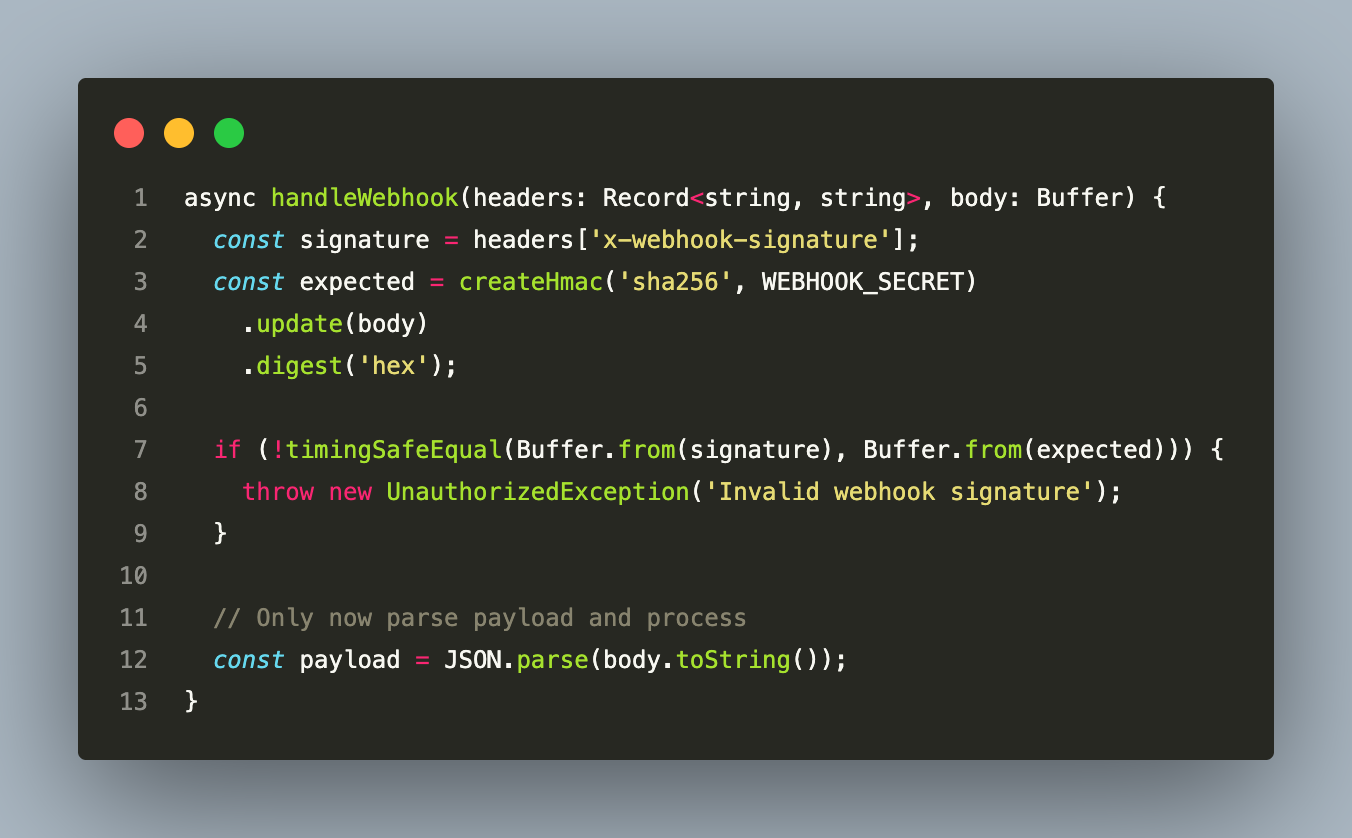
timingSafeEqual prevents timing attacks on the HMAC comparison. No DB reads, no business logic, no payload parsing before this check — a forged webhook request returns 401 in microseconds.
Layer 4 — HTTP Security Headers (Traefik Middleware)
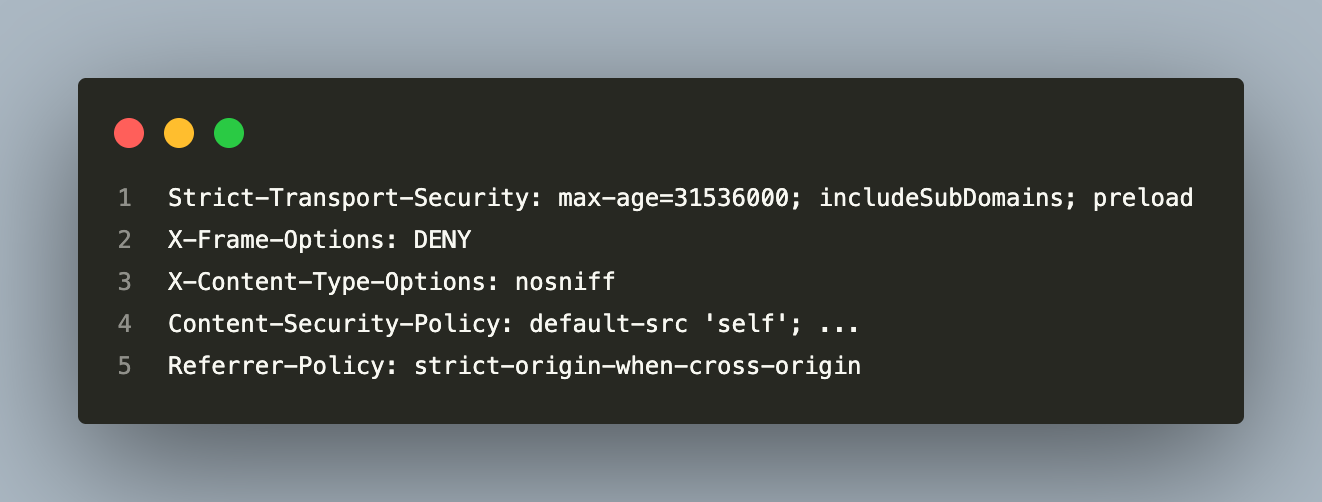
Applied by Traefik for every response. NestJS Helmet provides a secondary application-level layer for defence-in-depth. Security headers from two independent layers means a misconfiguration in one does not leave the response unprotected.
11. The Async Event Lifecycle
The event lifecycle is the most complex workflow in the system. It involves five components (HTTP API, gRPC, Bull queue, Redis counter, WebSocket), tables across two schemas, and conditional branching based on the event type.
Two Event Modes
A single boolean flag (is_condition_present) flips the entire winner-selection strategy:
is_condition_present = true → Social tasks required; winners selected post-event by point ranking
is_condition_present = false → Slot-machine mechanics; winners determined in real time via Redis
Full Lifecycle — Condition Mode
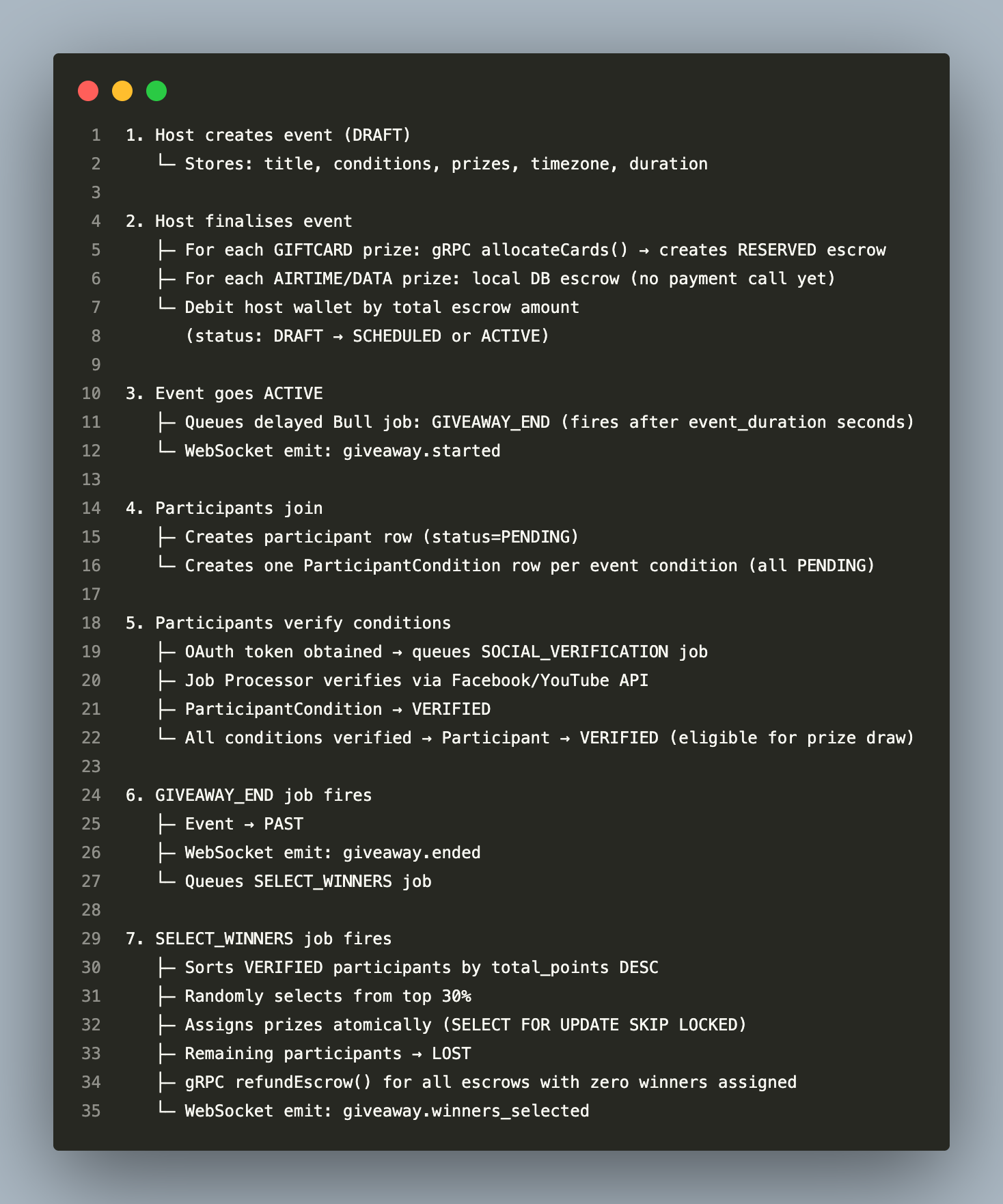
Full Lifecycle — Random / Slot-Machine Mode
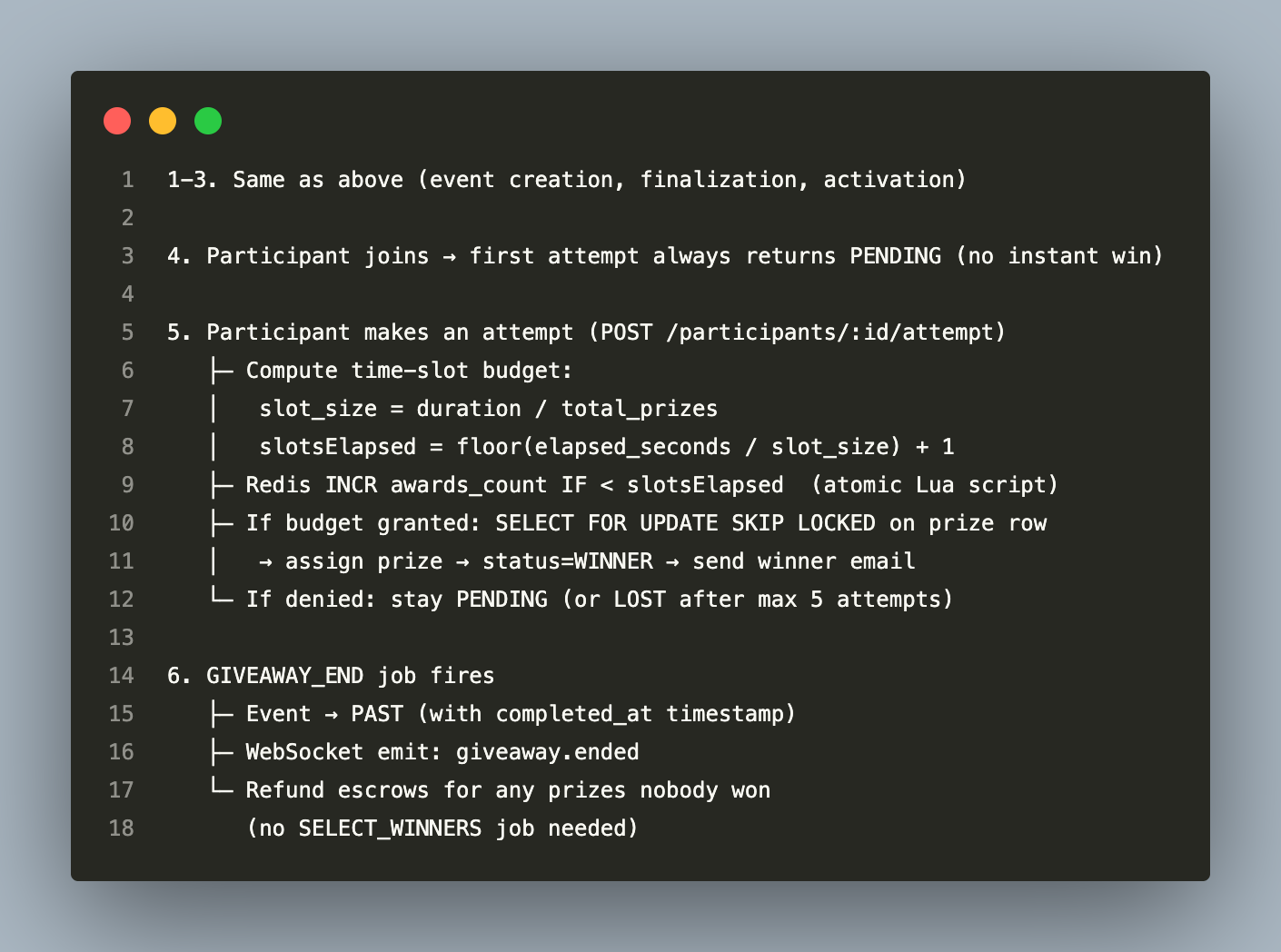
12. Frontend Integration — The Next.js Rewrite Pattern
The frontend is a Next.js 15 application. It communicates with both backend APIs through URL rewrites configured in next.config.js:
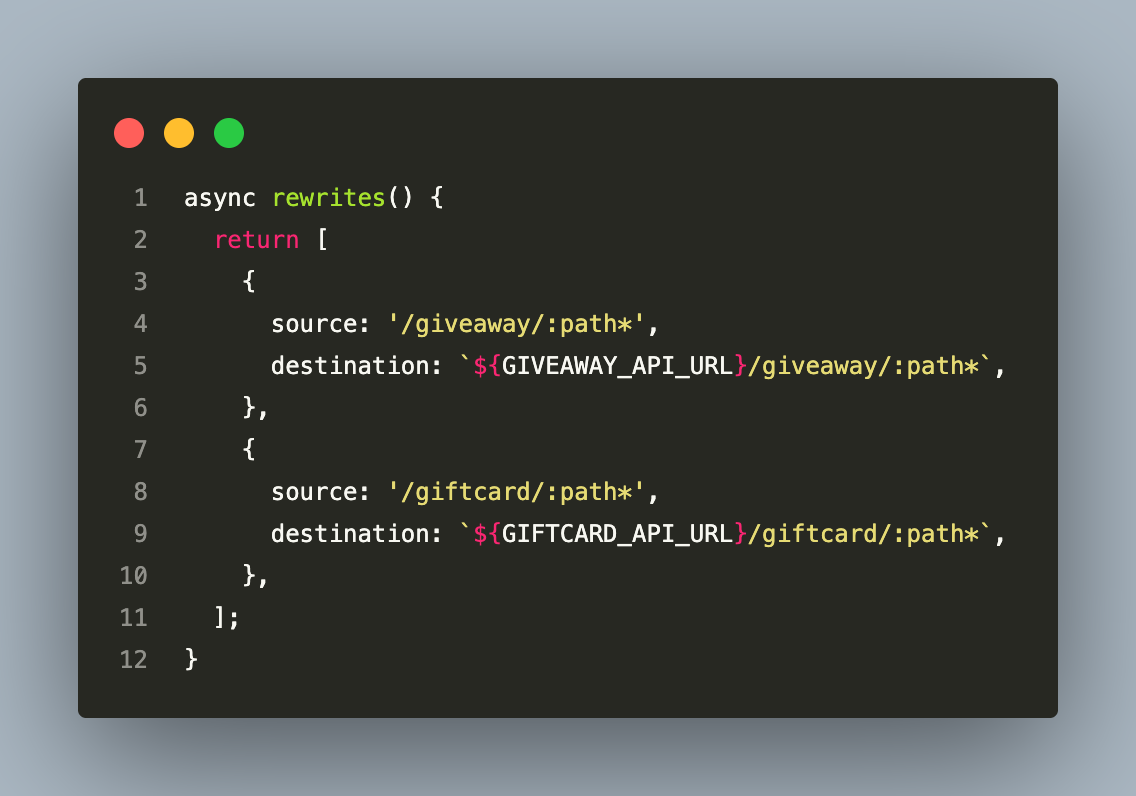
This pattern routes all /giveaway/* requests to the Giveaway API and all /giftcard/* requests to the Giftcard API without exposing either backend URL to the browser. The frontend acts as a lightweight BFF (Backend for Frontend) for routing purposes; all auth, business logic, and data fetching remain on the dedicated APIs.
The WebSocket connection is initialised once in a top-level context provider:
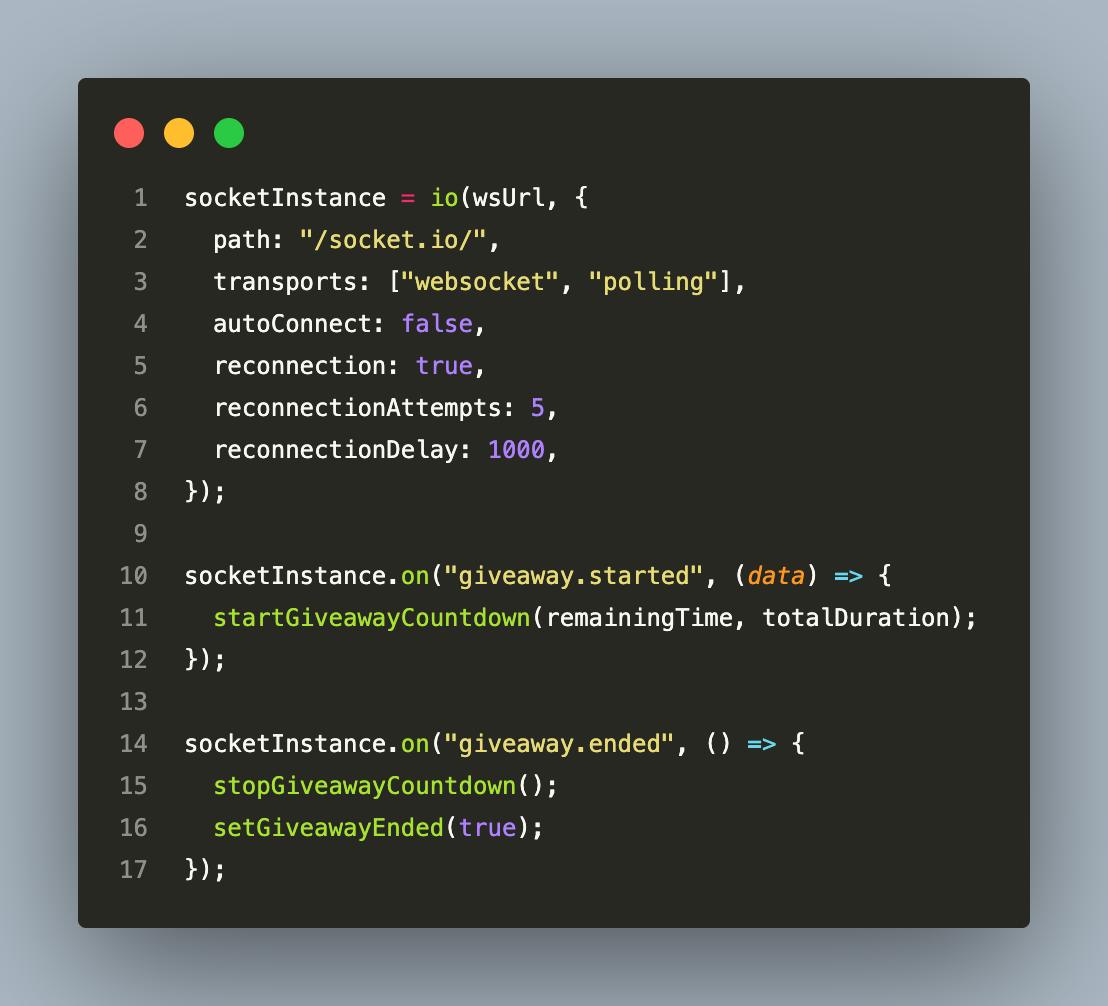
Event-specific rooms are joined when a participant enters the event page: socket.emit('join-giveaway-room', eventId). The gateway maintains the Socket.IO room membership; the Redis adapter ensures room state is shared across all gateway instances.
13. File Uploads — The Presigned URL Pattern
File uploads (event images, profile pictures, prize images) never pass through the API servers. Routing a 5 MB image upload through a Node.js HTTP server is wasteful — the event loop is occupied waiting for a large binary transfer when it could be handling hundreds of API requests.
Instead, a presigned URL pattern offloads the upload bandwidth entirely to object storage (Hetzner S3-compatible):
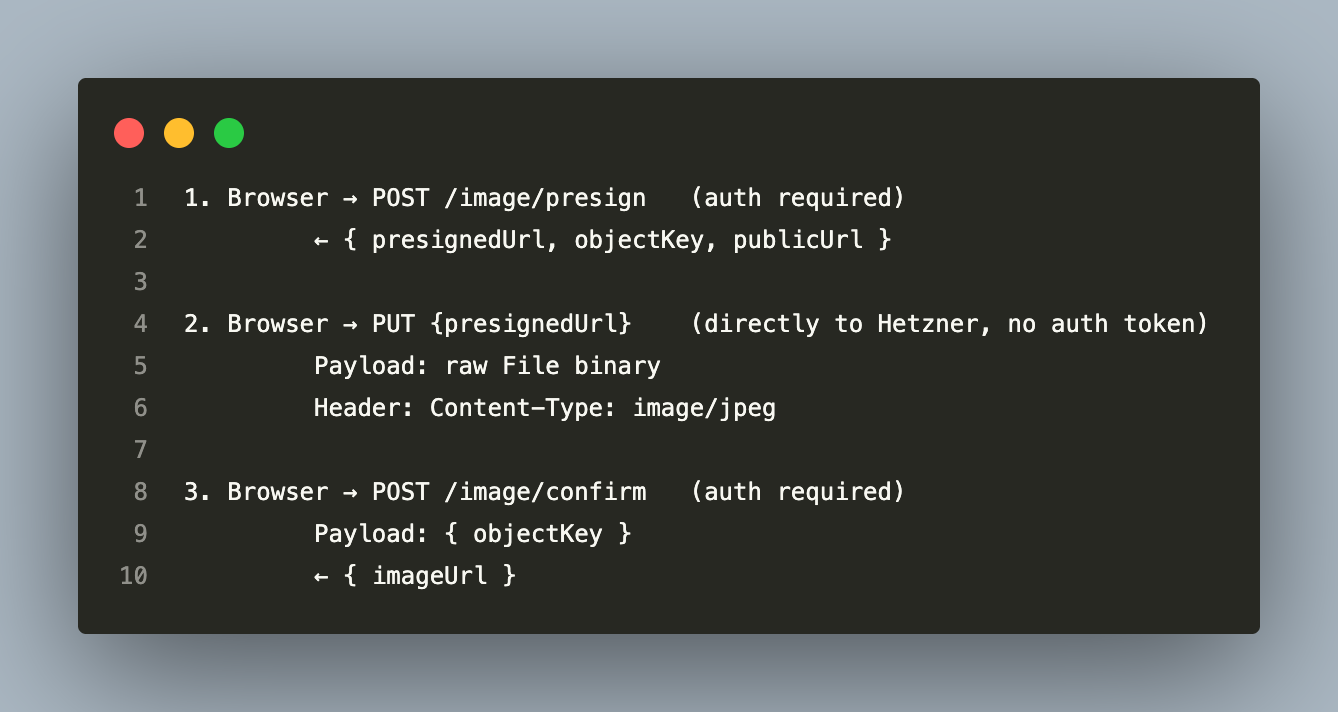
The backend issues a pre-signed URL to the frontend via the API — a time-limited, capability-granting URL that allows a PUT directly to the storage bucket:
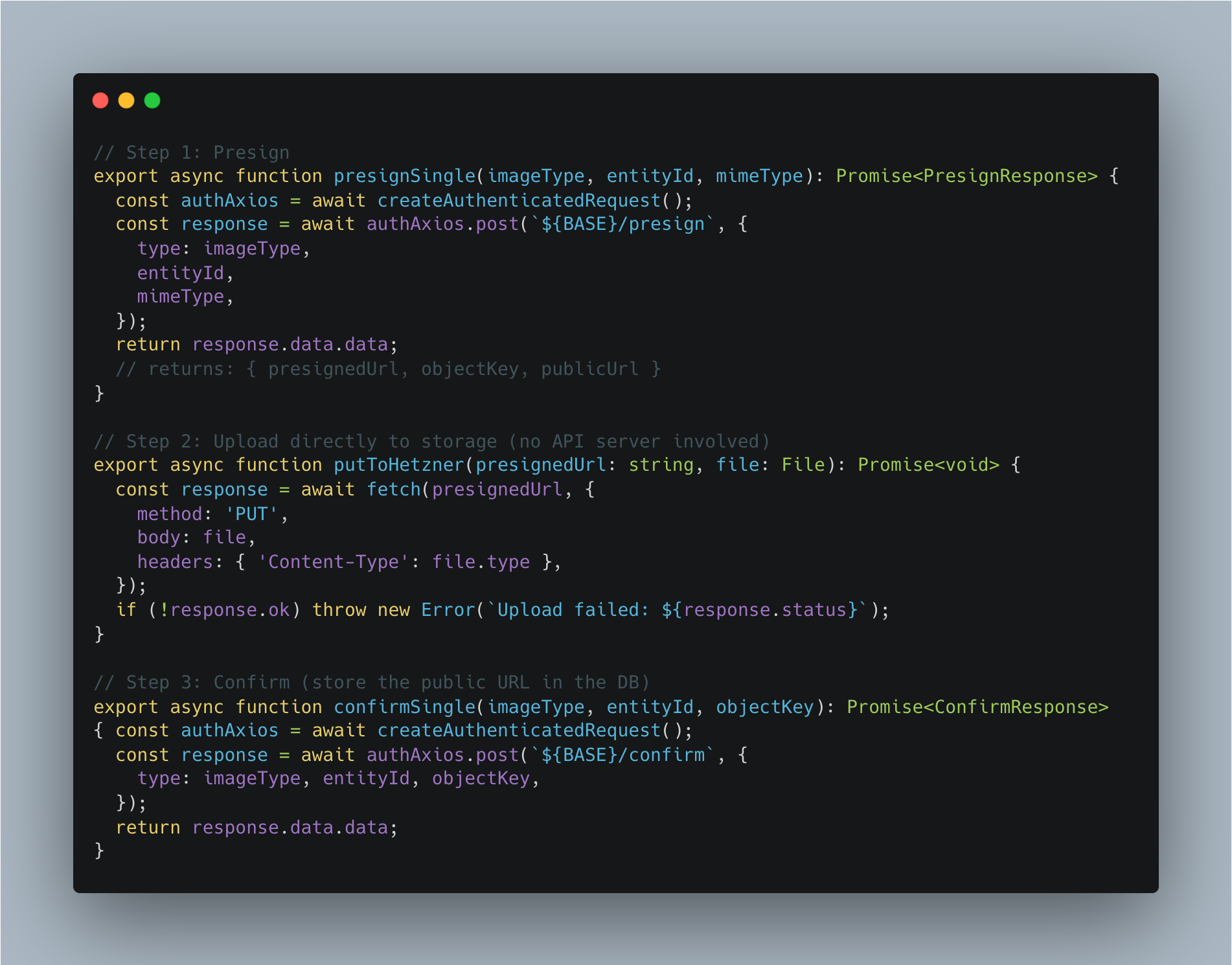
Why three steps instead of one?
- The presign step is JWT-authenticated and validates that the user has permission to upload this type of image for this entity. Unauthenticated requests cannot get a presigned URL.
- The PUT step goes directly from the browser to the CDN/storage layer. The API server is not in the upload path — no memory allocation for binary data, no multipart parsing, no I/O blocking.
- The confirm step closes the loop: it takes the objectKey returned from the storage service and persists the public URL into the database. Without this step, the backend has no record of the upload.
For bulk prize image uploads, a presign-bulk endpoint generates multiple presigned URLs in one round trip, and the confirm step accepts an array of keys:

The parallel Promise.all on the PUT calls means 10 prize images upload simultaneously, each in a separate TCP connection to the storage endpoint. From the user’s perspective, 10 images “upload at once” instead of one by one. Total upload time approaches the slowest single file, not the sum of all files.
14. Countdown Timers — Drift-Corrected Client-Side Ticking
A naive countdown timer uses setInterval with a 1-second delay and decrements a counter:

This accumulates error. Every JavaScript event loop tick is slightly longer than 1000ms due to scheduling jitter. After a 30-minute event, the client’s displayed time can be several seconds off from the server’s authoritative time.
The production implementation uses a target timestamp with drift correction:
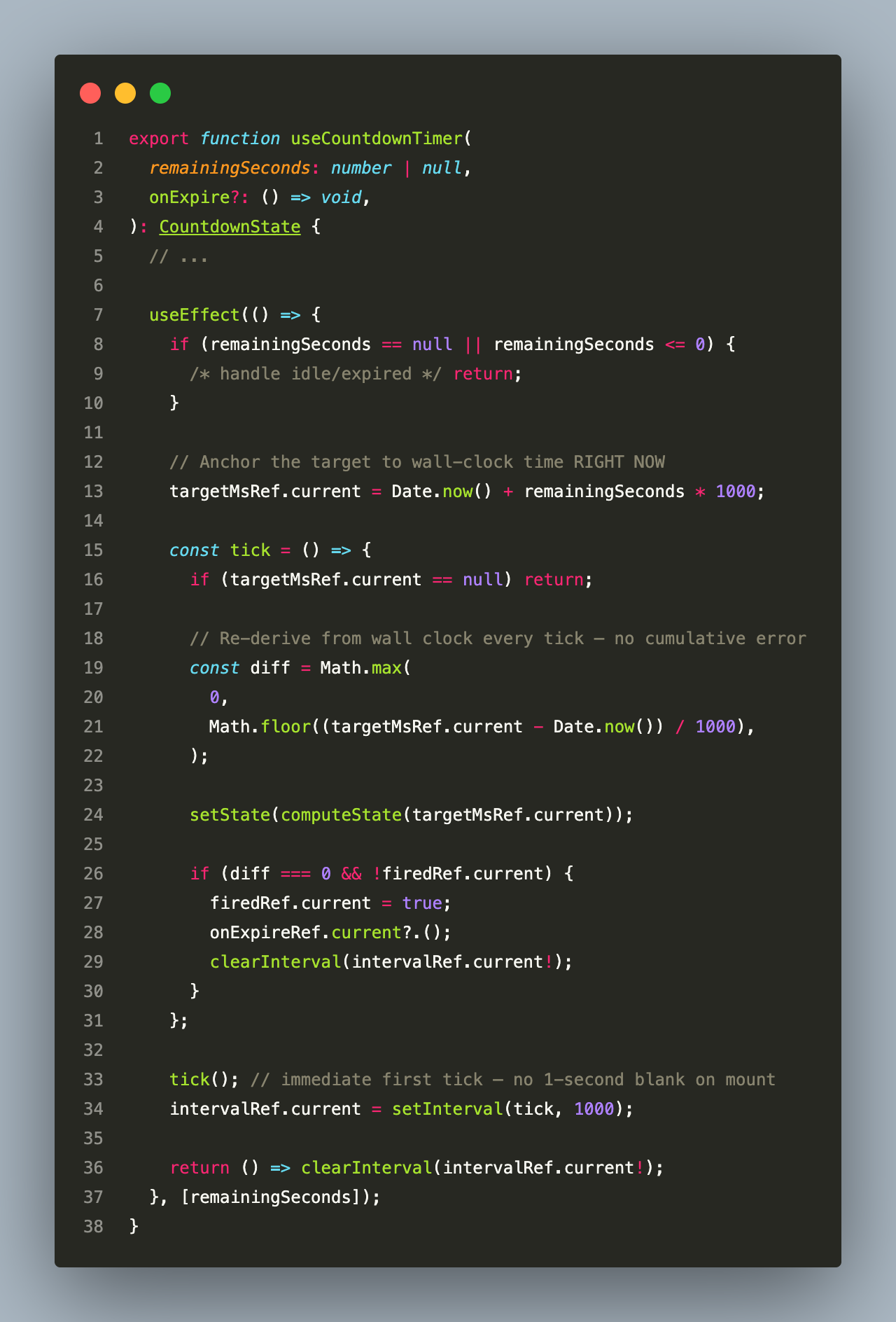
The key insight: targetMs is set once (Date.now() + remainingSeconds * 1000). Every subsequent tick derives the display value from targetMs - Date.now() — a subtraction from the current wall clock, not an accumulating decrement. If the event loop is busy for 1.2 seconds between ticks, the next tick will show N-2 seconds instead of N-1, but it will never be wrong by more than one tick.
The onExpire callback is stored in a ref rather than a closure, which means the caller does not need to memoize it with useCallback — changing the callback between renders does not restart the interval.
REST Hydration on Reconnect
The countdown’s authoritative source is the backend. When a user reconnects (page refresh, mobile background/foreground transition, WebSocket reconnect), the frontend cannot know how much time has passed since the last tick:
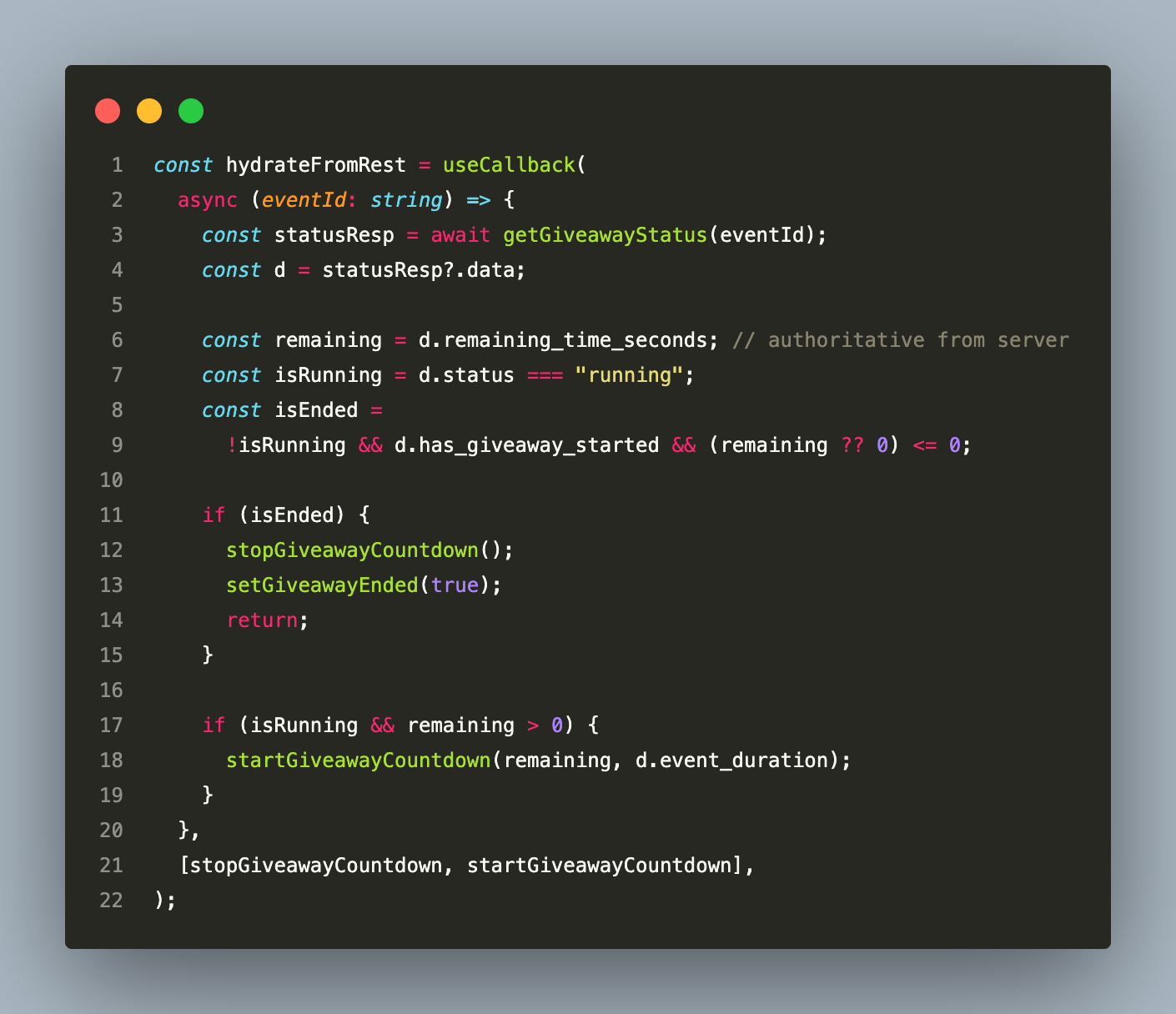
This is called on every WebSocket connect event (including reconnects) and on every room join. The server’s remaining_time_seconds restarts the countdown hook with a fresh target timestamp — any accumulated client-side drift is discarded. The pattern is: local timer for smooth display, server hydration for correctness.
Persisted Ended State
When the giveaway.ended WebSocket event fires, the ended state is persisted to localStorage:

On the next page load (or tab open), before the REST hydration completes, the component checks localStorage and immediately renders the ended state rather than showing “00:00:00” briefly followed by “ended”. This eliminates a visual flash without requiring server state for an already-completed event.
15. Infrastructure and Deployment
Multi-Stage Dockerfile
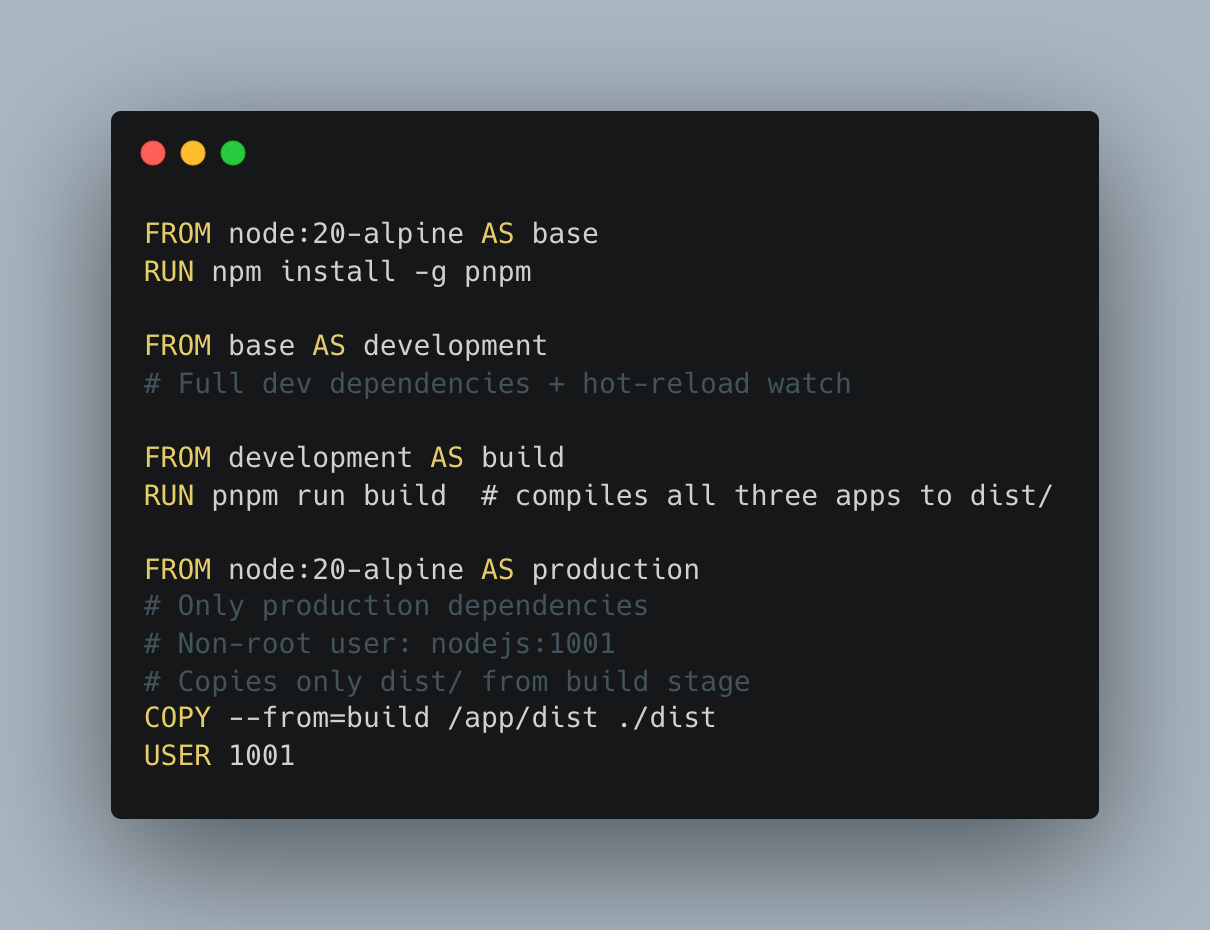
The production image contains no TypeScript compiler, no devDependencies, and no source files. The image is ~200 MB smaller than a naive build. The non-root user prevents a container escape from having root access to the host filesystem.
Docker Compose Startup Order
The production compose enforces a strict dependency chain via health checks:
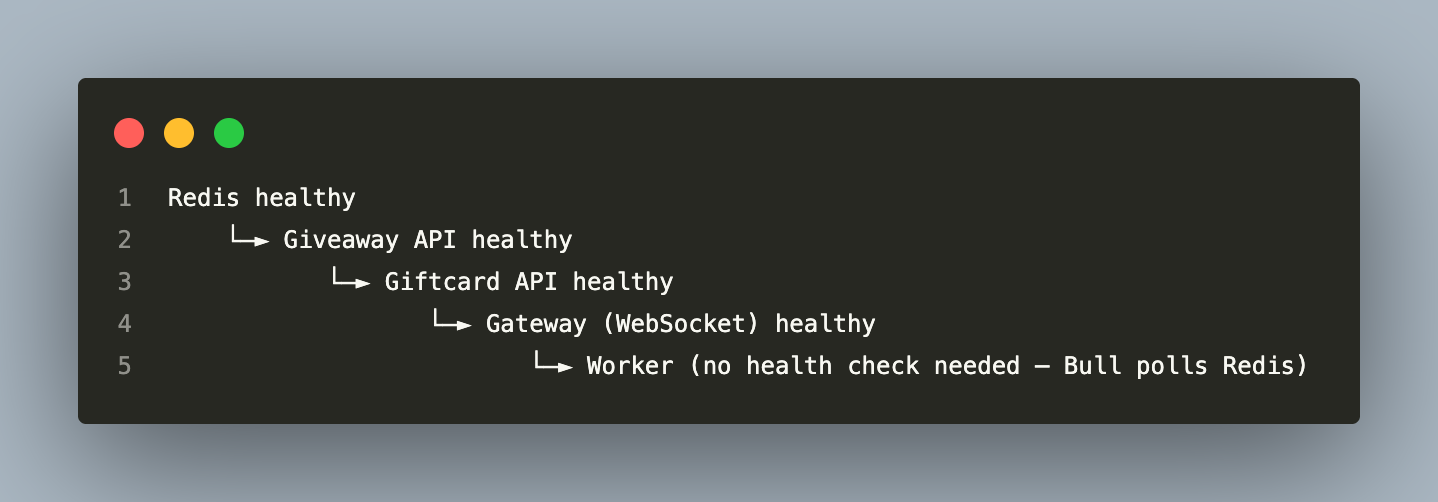
Each service’s depends_on references the upstream health check, not just the container start signal. A service that crashes on startup will not cause downstream services to launch against an unavailable dependency.
Traefik Path-Based Routing
Traefik is configured via Docker labels — no configuration file changes required when adding or redeploying services:
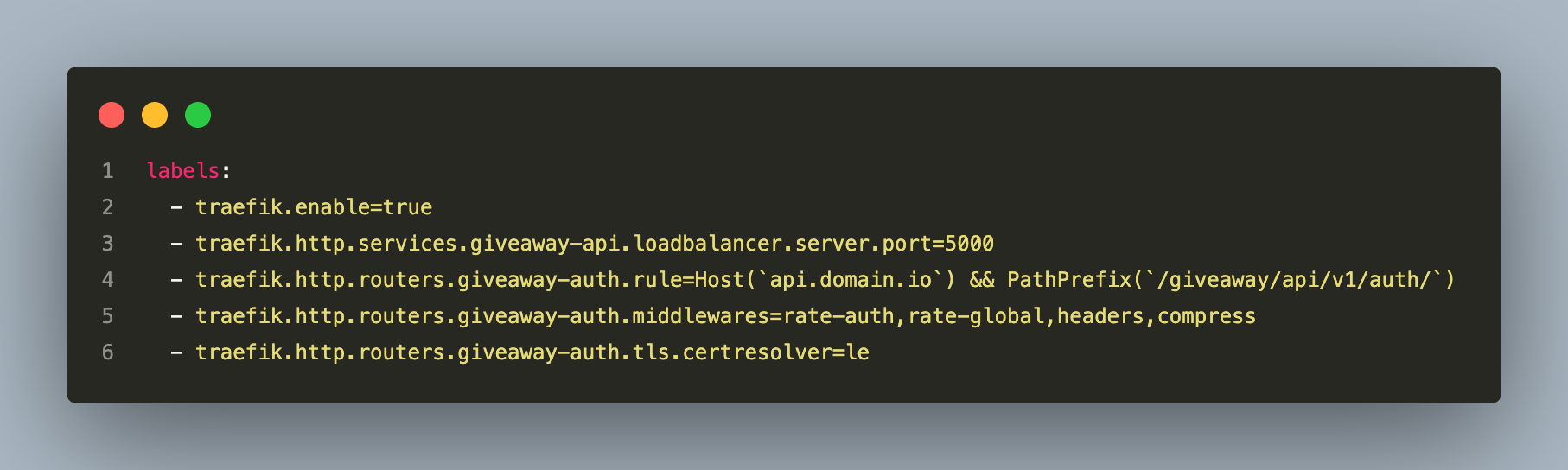
Auth routes get the strictest rate limiting middleware. General API routes get standard limits. The Socket.IO route has no sticky session requirement — all gateways share room state via Redis, so any gateway can serve any client.
Let’s Encrypt certificates are managed automatically. Traefik polls ACME and renews certificates before expiry with zero downtime.
CI/CD Pipeline
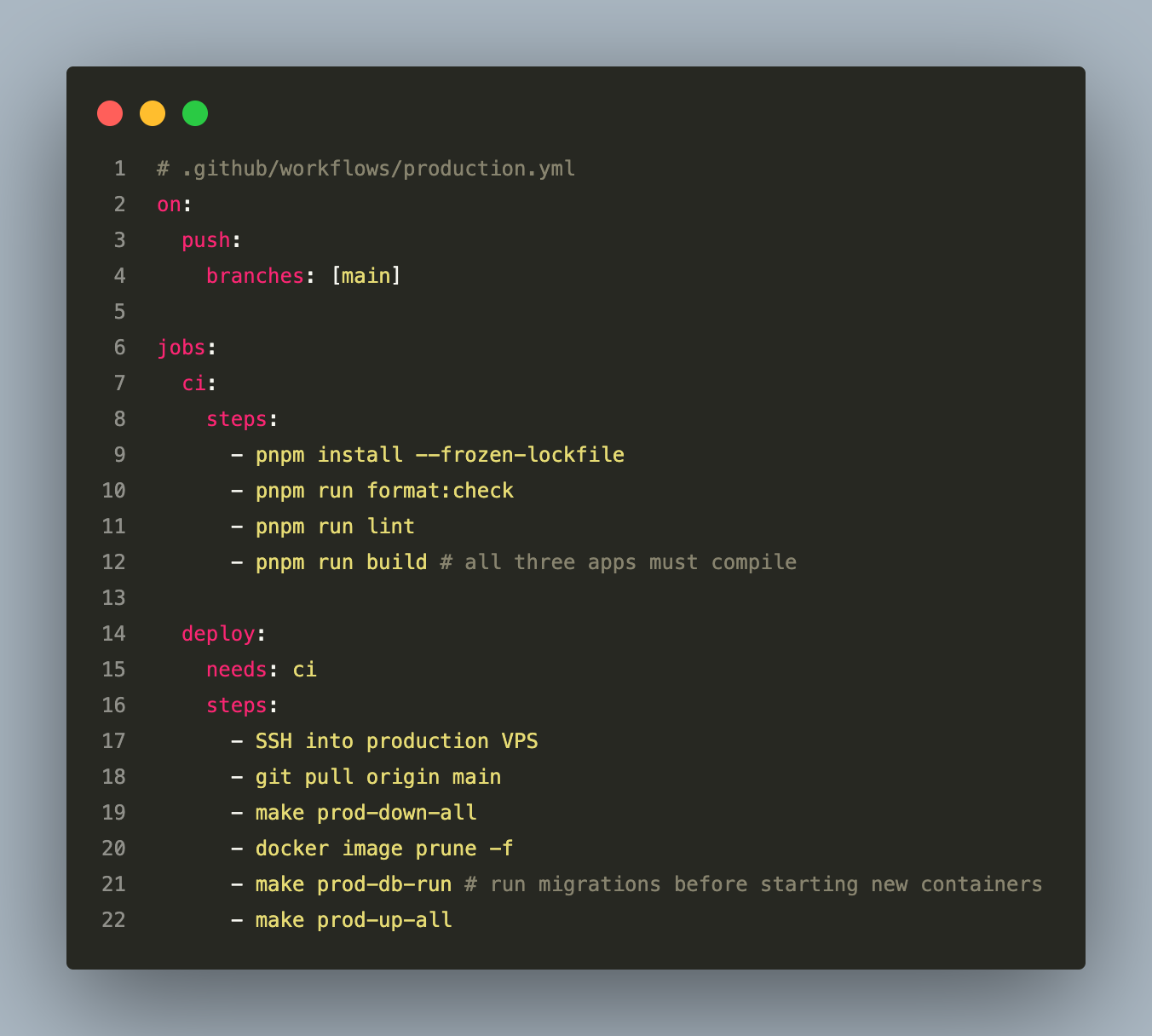
Migrations run before containers start — this guarantees the new code never starts against an old schema. A failed migration aborts the deploy before any service restarts.
16. Capacity Analysis — How Many Users Before Something Breaks?
The Bottleneck Stack
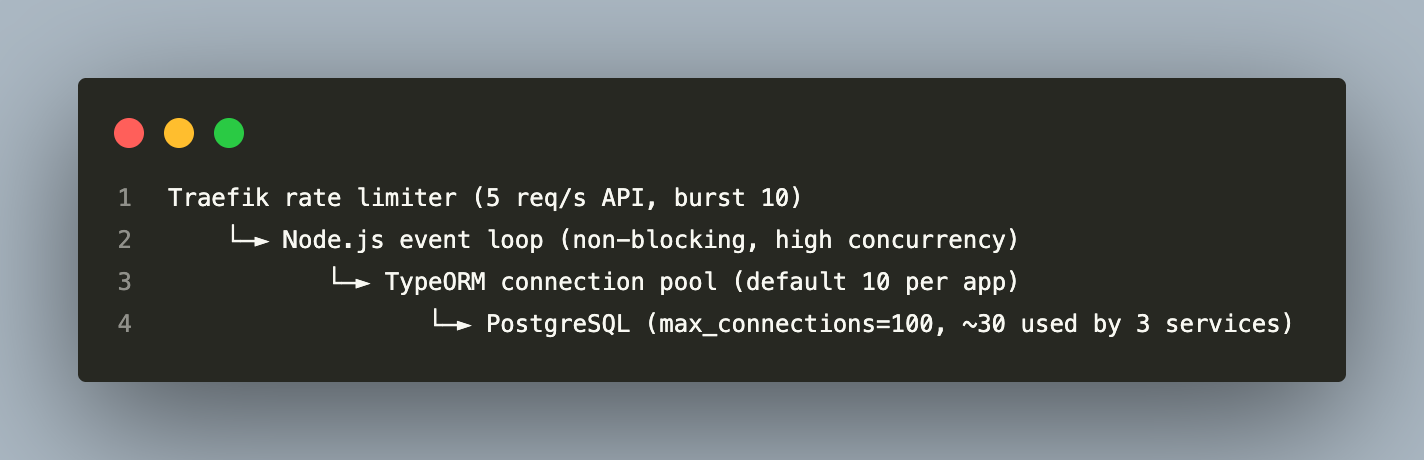
The TypeORM connection pool is the first hard limit. With the default of 10 connections per app, three services consume 30 connections total. PostgreSQL’s default max_connections=100 leaves headroom, but the pool itself becomes the bottleneck before PostgreSQL does.
Capacity by Workload Type
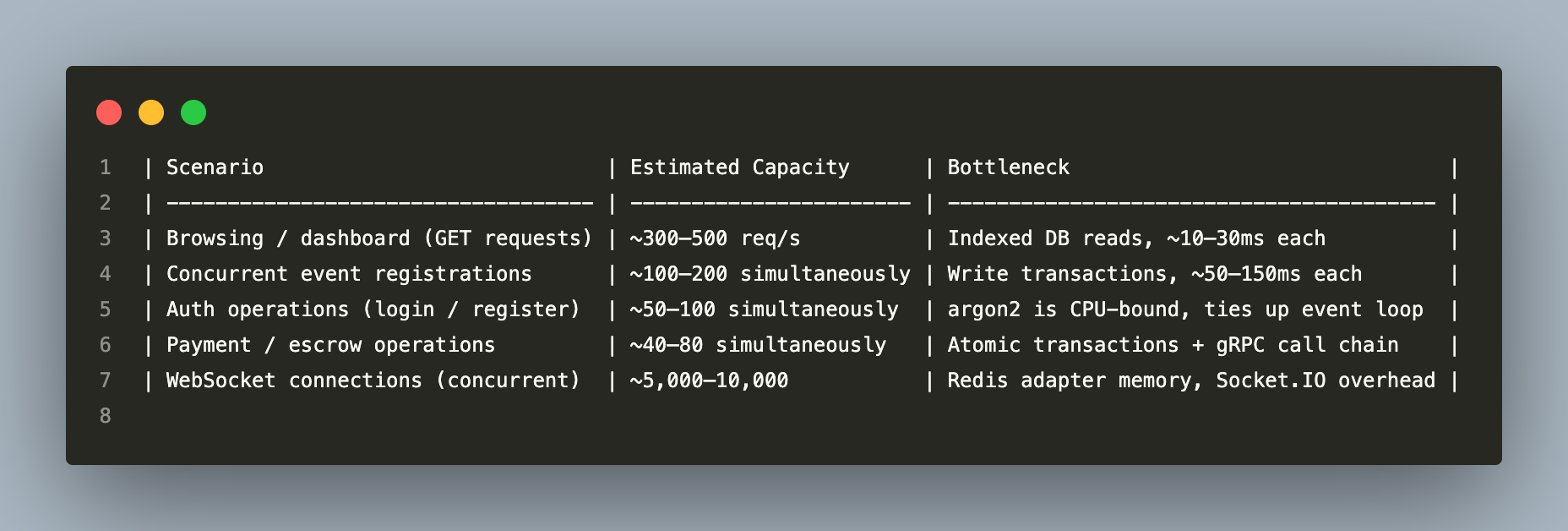
Live Event Stress Scenario
500 participants register simultaneously during a spike: - Default pool of 10 connections on the giveaway API - First 10 requests hit the DB immediately (~50ms each) - Remaining 490 queue in Node.js memory (non-blocking — they do not fail, they wait) - At ~50ms per write: ~200 registrations/second → 500 people done in ~2.5 seconds - At 2,000 simultaneous registrations: queue grows to ~10 seconds — noticeable but not broken
The single most impactful configuration change, zero infrastructure cost:
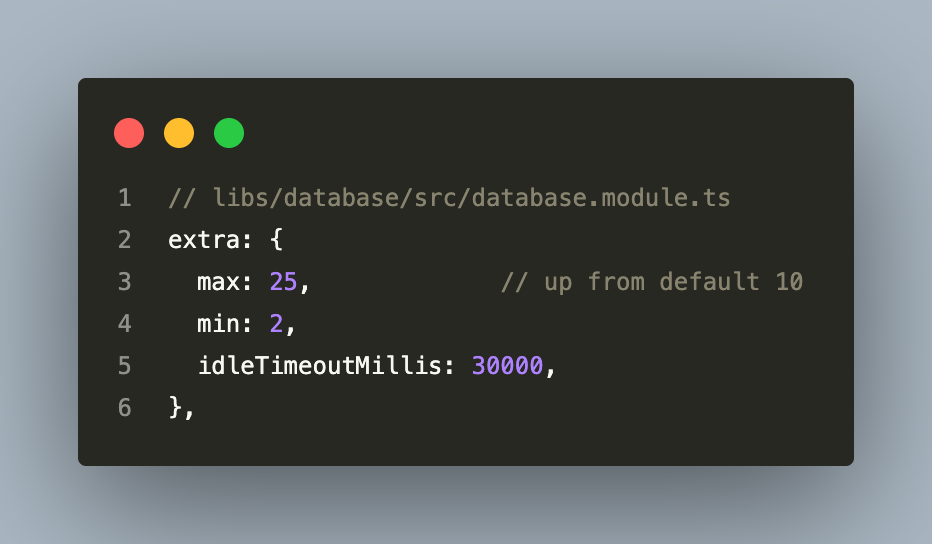
Three services × 25 connections = 75 active connections. Still under PostgreSQL’s default max_connections=100. This nearly triples concurrent write capacity with zero infrastructure cost.
The User Ceiling — Honest Numbers
With the current single-VPS setup (8 vCPU / 16 GB RAM), tuned connection pools, and the described architecture:
Comfortable operational range: 1,000–3,000 concurrent active users
Where “active” means users simultaneously making write requests (registrations, purchases, redemptions). Passive users (browsing, watching the countdown) can scale considerably higher because their requests hit the Redis cache and complete in ~5ms — they barely touch the DB pool.
Upper practical bound before degradation starts: 3,000–5,000 concurrent users
Beyond this point, the connection pool queue grows long enough (>5 second wait) that users perceive the system as slow, even though it is not failing.
WebSocket ceiling: 5,000–10,000 concurrent connections on a single gateway instance. Redis adapter scales this linearly with additional gateway instances.
Total registered users the system can serve comfortably: Tens of thousands, assuming not all of them are simultaneously active at write-heavy operations. A typical usage pattern (10–20% concurrently active) puts the comfortable total user base at 15,000–30,000 registered users on the current hardware.
17. Scaling Additions — When and How
Stage 1 (Current) — Single VPS, Docker Compose
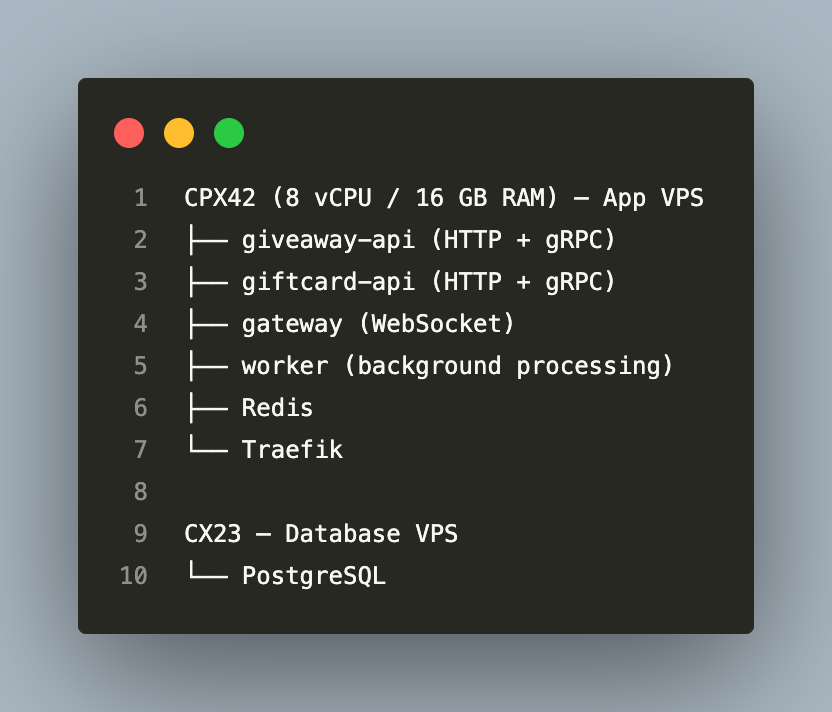
Handles comfortably: 1,000–3,000 concurrent active users, 5,000 WebSocket connections, live events with 500–1,000 simultaneous participants.
Optimisations at this stage (no infrastructure change): - Increase TypeORM pool sizes to 25 - Enable Redis maxmemory-policy allkeys-lru to prevent OOM on cache key accumulation - Set max_connections=200 on PostgreSQL with pgBouncer as a connection pooler
Stage 2 — More Workers (Same VPS)
When queue backlog grows consistently (emails delayed, event draws processing slowly):
Each additional worker costs ~100–150 MB RAM and negligible CPU between jobs. CPX42’s 16 GB can run 4–5 workers comfortably. No code change, no infrastructure addition.
Handles: 3×–5× the background job throughput. Live events with thousands of participants submitting social verifications simultaneously.
Stage 3 — Separate Redis VPS
Trigger: When you need to add a second app VPS for horizontal scaling of the API services. All instances must share one Redis.
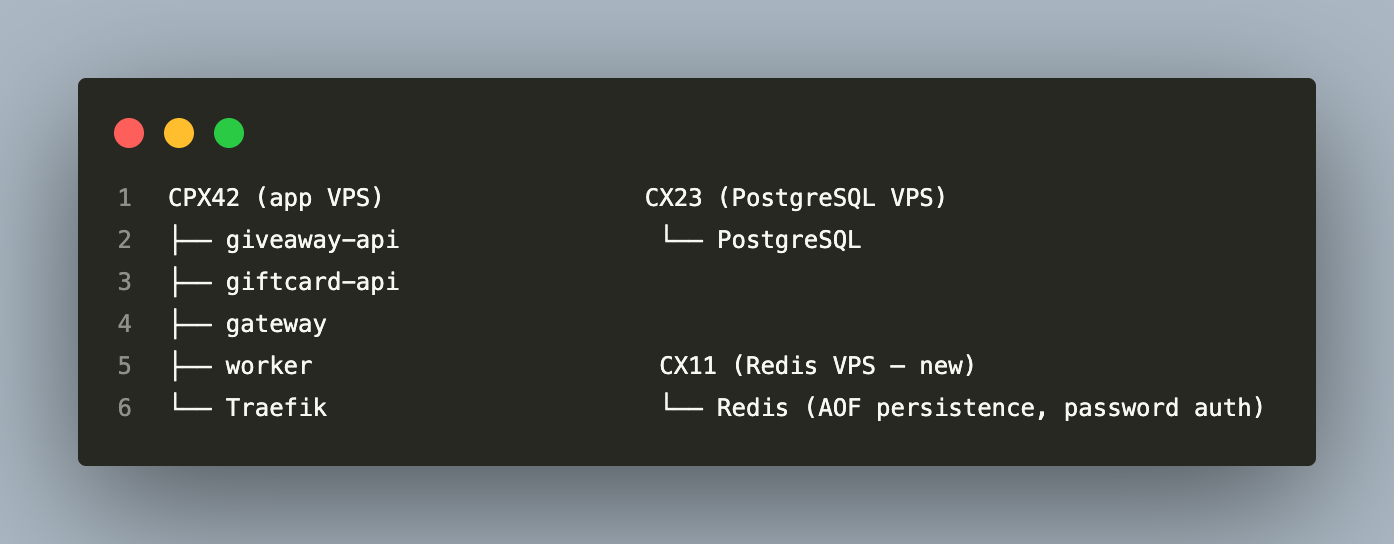
Migration procedure:
1. Provision Redis on a new CX11 VPS (same datacenter, private network, <1ms latency)
2. Start Redis replication: REPLICAOF <old_redis_ip> 6379
3. Wait for master_link_status:up and replication offset convergence
4. Stop workers (drain queues to zero — check LLEN bull:EVENT_PROCESSING:wait)
5. Stop all apps
6. Promote new Redis: REPLICAOF NO ONE
7. Update REDIS_URL in all containers to new IP
8. Restart, verify, then decommission old Redis after 24 hours
What Redis data to preserve: Bull queue jobs (waiting/delayed). Not worth migrating: Socket.IO room memberships (clients reconnect automatically), awards counters (per-event, zero between events).
Stage 4 — Horizontal API Scaling
Trigger: DB pool and queue backlog are healthy, but API response times are elevated under sustained load (event loop saturation from concurrent requests).
Add a second app VPS pointing at the same Redis and PostgreSQL. No code changes required — all state is externalised.

Traefik on VPS 1 load-balances across both. Socket.IO rooms are already synchronised via Redis adapter — no sticky session configuration needed.
Stage 5 — Kubernetes
Trigger: 3+ VPS nodes needed, and the manual Docker Compose approach becomes operationally expensive to manage.
K8s earns its complexity when you need: - Multi-node scheduling and pod bin-packing - Auto-scaling pods based on CPU or queue depth metrics - Rolling deployments with zero downtime and automatic rollback - Self-healing across node failures
The current architecture is already K8s-ready: - All services are stateless (state in Redis and PostgreSQL) - All configuration is externalised via environment variables - Health checks are defined on every service - Redis adapter is wired for multi-instance Socket.IO - No hard-coded service discovery — container names resolve via DNS
A migration from Docker Compose services to Kubernetes Deployments is nearly 1:1. Each docker-compose service becomes a Deployment + Service. The Traefik labels become Ingress annotations. Volumes become PersistentVolumeClaims.
K8s overhead on a single node (K3s): ~800 MB–1.2 GB RAM. On a 16 GB VPS, that is not prohibitive, but it is overhead for zero practical gain when Docker Compose already handles everything correctly. The migration is deferred until it genuinely earns its complexity — not based on traffic volume alone, but on the need for multiple VPS nodes.
18. Non-Obvious Design Decisions
Finalization Uses a Saga Compensation Pattern, Not a Distributed Transaction
Event finalization crosses two service boundaries in a sequence that cannot be wrapped in a single atomic unit:
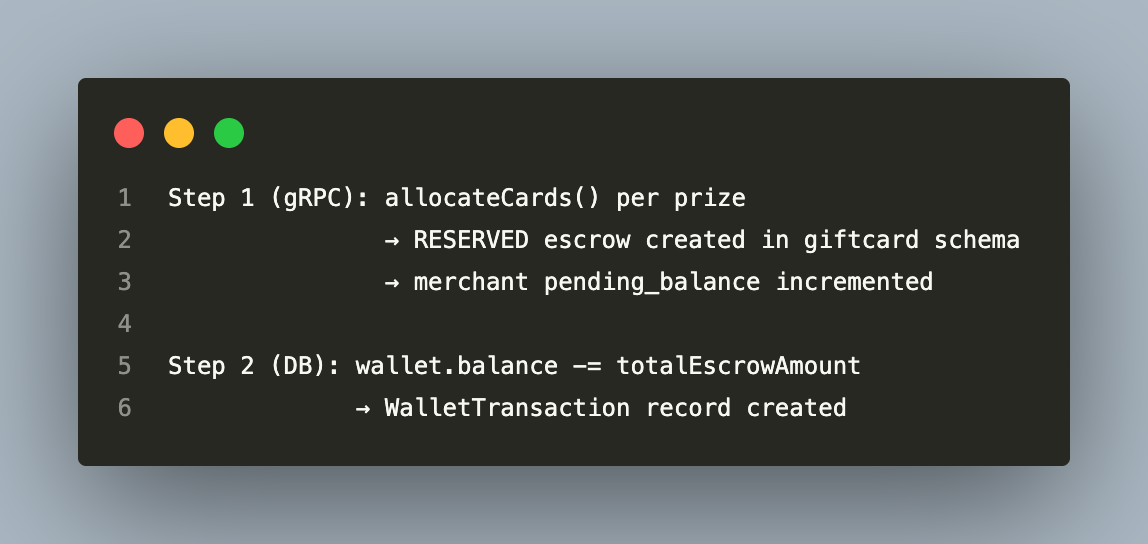
The system handles partial failures with inline saga compensation — if Step 2 fails after Step 1 has partially or fully completed, any escrows created in that run are refunded before the error is re-thrown:
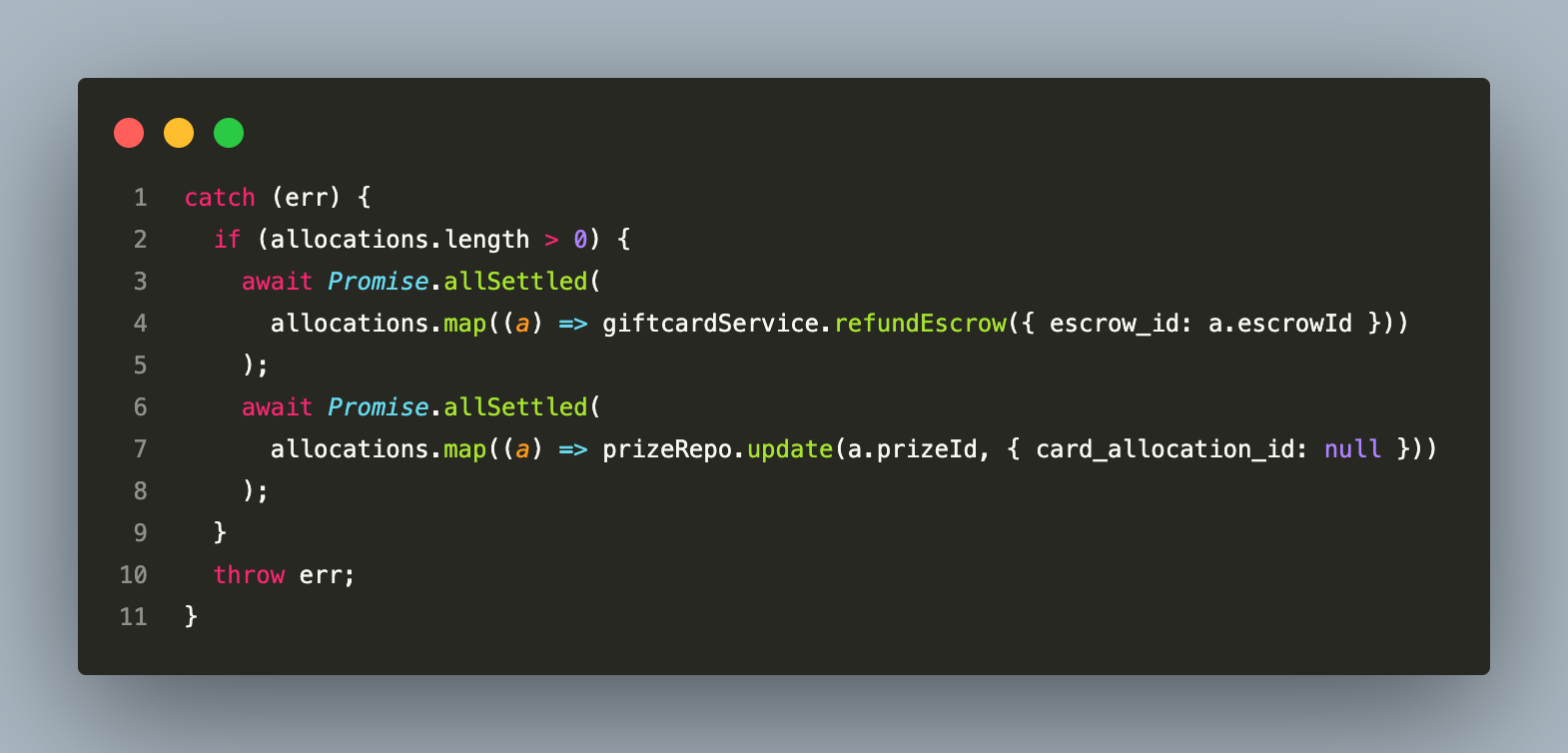
Promise.allSettled is deliberate — a failed refund on one prize does not prevent the others from being refunded. Clearing card_allocation_id regardless of refund success prevents a double-refund if the caller retries. The pre-flight balance check (wallet.balance >= totalEscrowAmount) runs before any gRPC call, so the failure surface is limited to infrastructure errors rather than business logic.
Telecom Prize Vend Failure Auto-Refunds the Host Wallet
When a winner claims a telecom prize (airtime or data), the payment provider is called immediately. If the provider fires a payout_failed webhook, the system automatically credits telecom_amount back to the host wallet in a DB transaction:
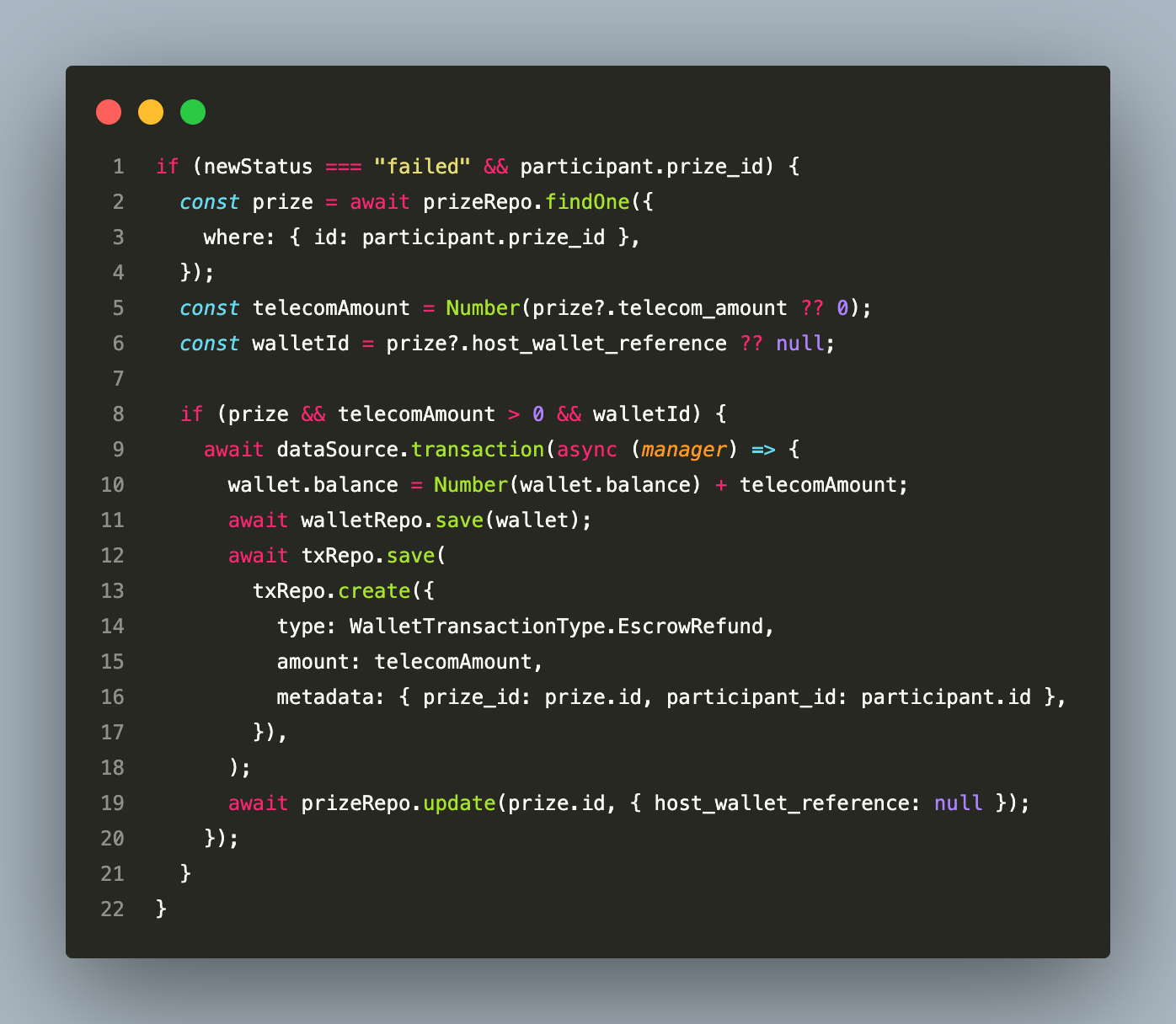
Clearing host_wallet_reference after the transaction is the idempotency guard — if the webhook retries, the prize no longer has a wallet reference and the refund branch is skipped cleanly.
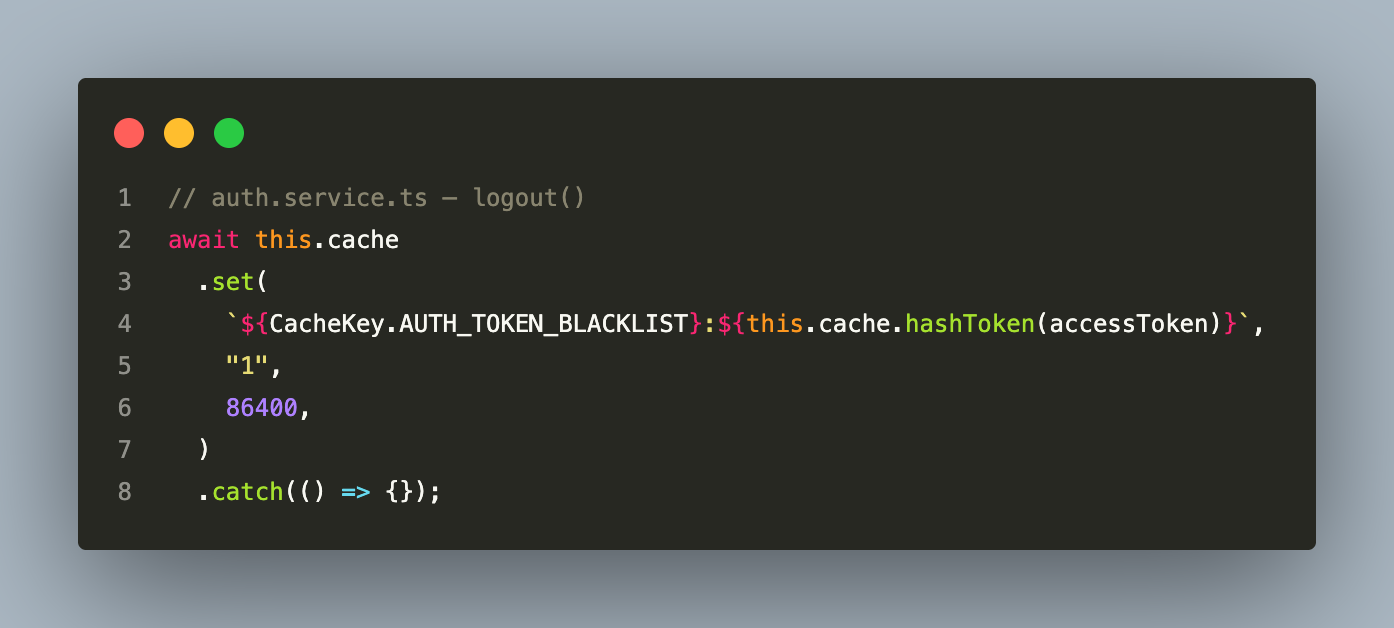
Token Invalidation Uses Redis Hashes, Not a Database Column
Logout token invalidation is handled entirely through Redis. When a user logs out, the SHA-256 hash of the access token is written to Redis with a 24-hour TTL — equal to the maximum access token lifetime:
On every authenticated request, the JWT strategy performs a single O(1) Redis GET against the token hash. The auth table is not joined for this check — the strategy queries only the users table:
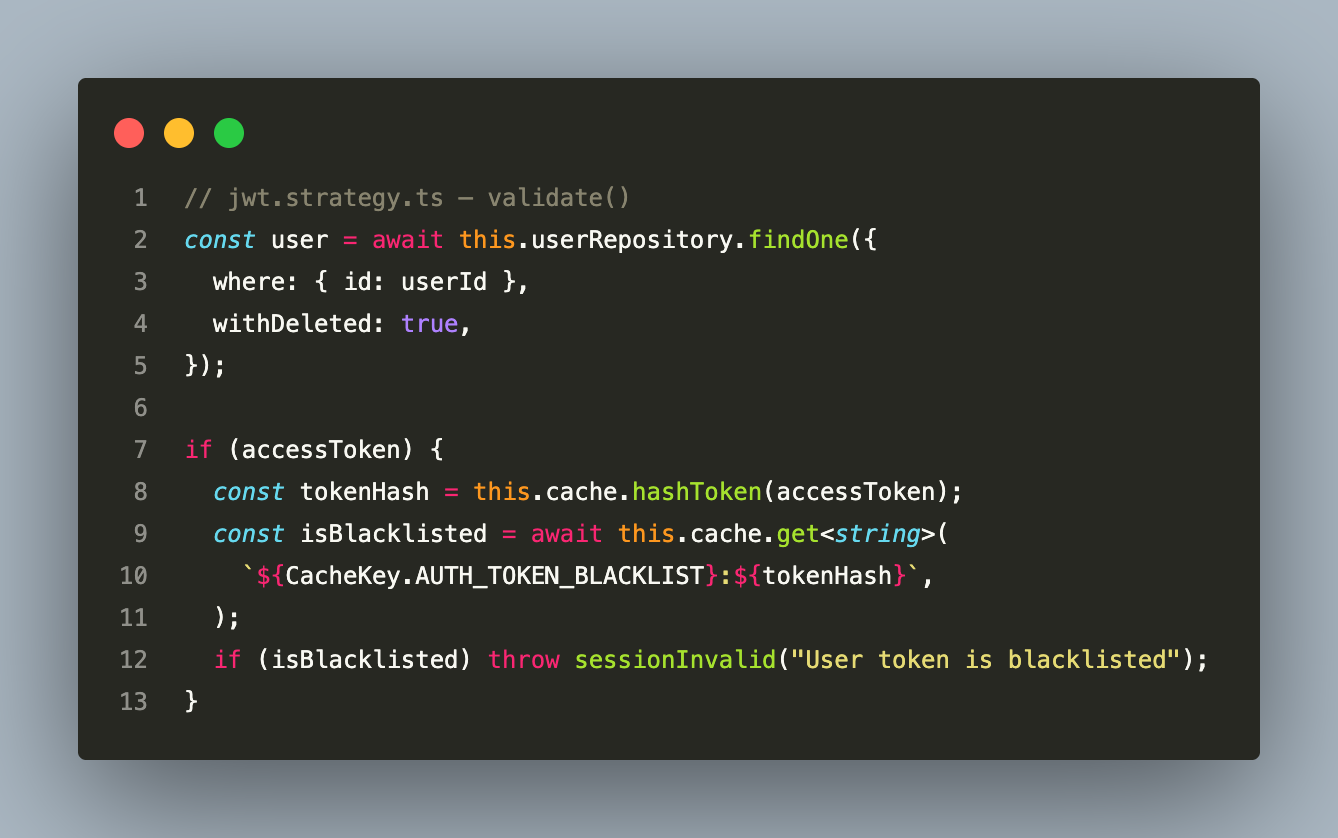
Storing the hash rather than the raw token is a security property — the Redis key cannot be used to replay the original token. Keys expire automatically via TTL; no background cleanup job is needed.
19. Shared Library Design — The @shared Module
One of the cleaner architectural decisions is the SharedModule being decorated with @Global():
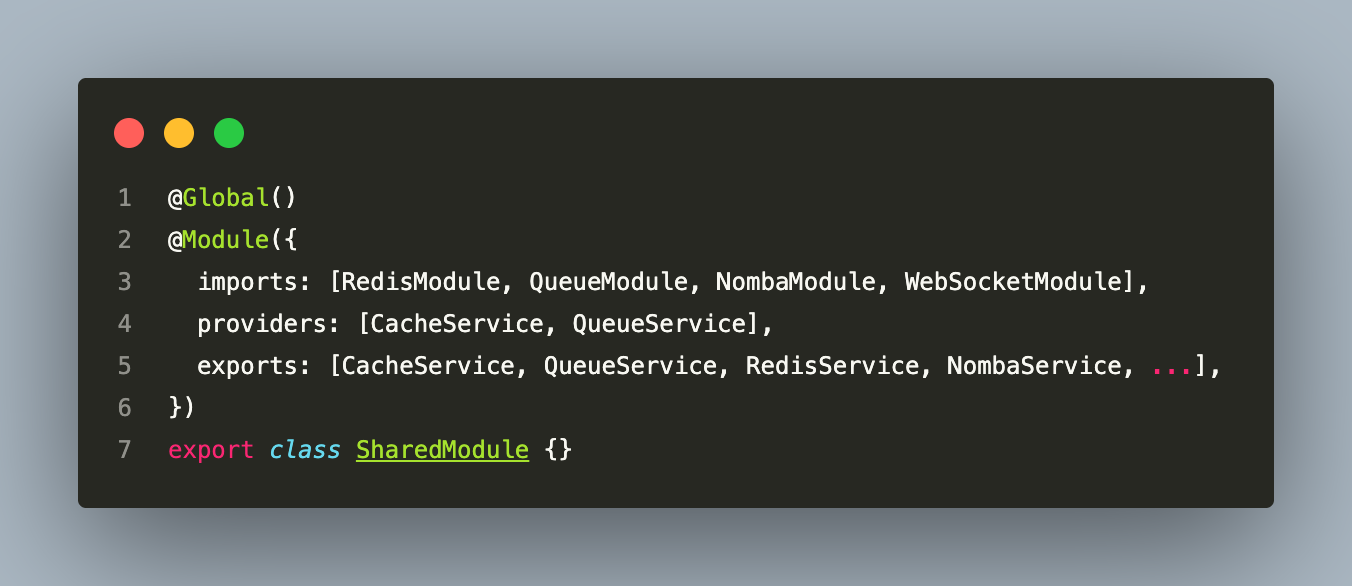
Once ‘SharedModule’ is imported at the root level of each app module, every downstream module can inject CacheService without explicitly importing a cache module. This eliminates boilerplate at the cost of making the dependency slightly less visible — you need to know the global module convention to understand where CacheService comes from in a feature module’s injection.
For a codebase of this size with a small team, the tradeoff favours removing the boilerplate. At a larger scale with many teams, explicit imports (even if repetitive) are easier to audit.
20. Observability
The observability stack is deliberately split into two layers: infrastructure visibility for the engineering team, and structured error responses for end users. These are explicitly kept separate — an internal Nomba transfer failure is an engineering concern, not something a user should ever see.
Sentry — Infrastructure Error Capture (Production Only)
Sentry is initialised via “SentryModule.forRoot()” in production. Every infrastructure boundary — Nomba webhook processing, gRPC call failures, Bull queue job failures, Redis errors — captures exceptions directly to Sentry. These are internal errors that indicate infrastructure problems, not user input errors, so they must not surface to the frontend as readable messages.
The pattern is applied consistently at every failure boundary:
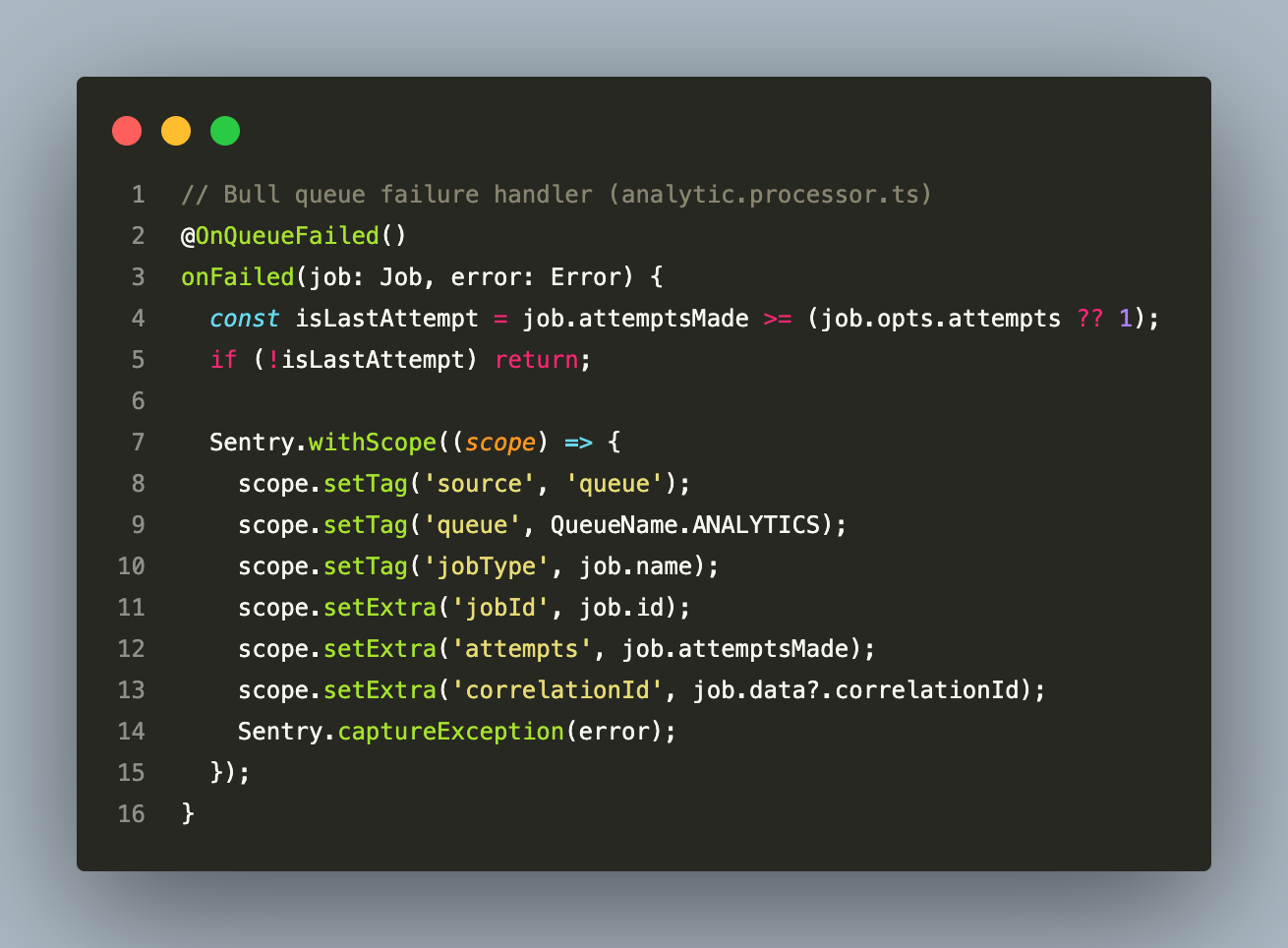
The same approach applies to gRPC call failures (circuit breaker opens → Sentry), Nomba webhook parsing errors, and any unhandled exception that escapes the global `ErrorFilter`. In development and staging environments, Sentry capture is disabled — errors surface only in the NestJS logger so they are visible locally without polluting the production error stream.
Why production-only? Development generates noisy infrastructure errors constantly — Redis not yet connected, gRPC service starting up, test webhook payloads. Capturing all of that into Sentry would drown out the signal from real production failures.
The User/Infrastructure Error Boundary
User-facing errors (validation failures, not-found, unauthorised) are returned as structured HTTP responses via `ErrorInterceptor` and `ErrorFilter`. Infrastructure errors (payment provider down, gRPC timeout, queue overflow) are caught, logged to the NestJS logger, and captured to Sentry — they never propagate as HTTP 500 responses with internal stack traces. The user sees a generic "something went wrong" message; the engineering team sees the full context in Sentry.
Correlation IDs — Cross-Process Request Tracing
Every HTTP request carries an `x-correlation-id` header, injected by `CorrelationInterceptor`:
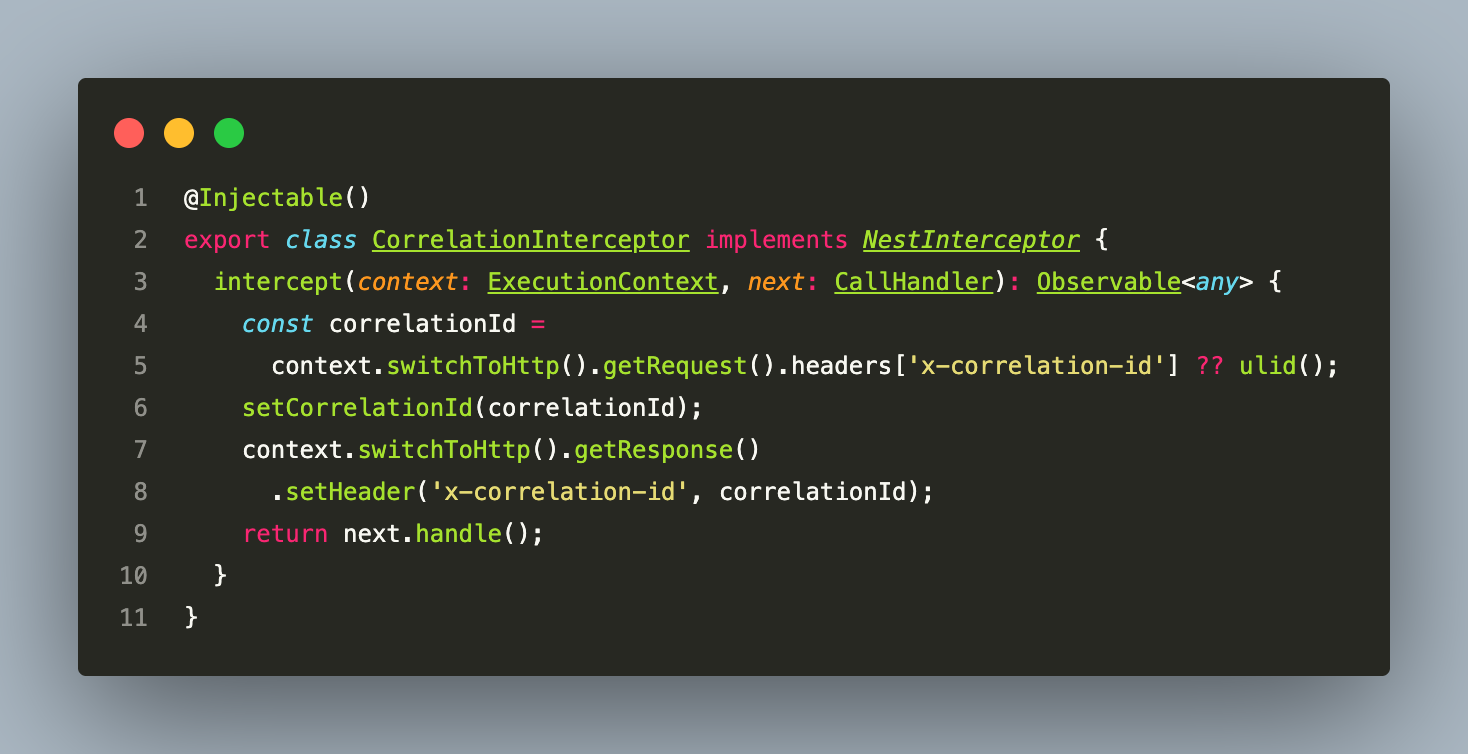
All Bull jobs enqueued by `QueueService` carry the originating request's correlation ID. When a social verification job fails 90 seconds after the original HTTP request, the Sentry capture includes the correlation ID — making it possible to trace the failure back to the originating user action without a dedicated distributed tracing platform.
Infrastructure-Level Monitoring
Hetzner Cloud console — CPU, RAM, disk, and network graphs for every VPS out of the box. No install required. Sufficient to detect if a container is consuming excessive memory or if network throughput spikes before an event.
Docker stats — `docker stats` gives per-container CPU and RAM in real time. The first signal that a Node.js process is leaking memory or that a Bull queue worker is under sustained CPU load comes from here.
Summary — What This Architecture Gets Right
Separation of concerns without over-engineering. Three apps instead of ten microservices. Each has a clear, coherent domain boundary. Cross-cutting infrastructure is shared via a global module. Services communicate via strongly-typed gRPC contracts, not HTTP JSON strings.
Redis as a multi-functional platform primitive. The same Redis instance handles queuing, caching, WebSocket room management, and atomic concurrency control. No Kafka, no separate cache cluster, no dedicated counter service. One Redis with four distinct jobs.
Financial correctness without distributed transactions. The escrow state machine, idempotency keys on every financial operation, HMAC webhook validation, and the deliberate ordering of DB writes versus external calls collectively ensure that money moves correctly even under failure, retry, and concurrent load.
File upload offloading via presigned URLs. Binary data never touches the application servers. The presign → direct PUT → confirm pattern gives the API control over authentication and authorization while keeping the event loop free from large binary I/O.
Drift-corrected countdowns instead of naive decrementers. Target-timestamp anchoring on the client ensures display accuracy across the full event duration, even under JavaScript event loop jitter. REST hydration on every reconnect keeps the client synchronised with the server’s authoritative state.
Scaling that compounds correctly. Adding workers scales queue throughput. Adding gateways scales WebSocket capacity. Separating Redis to its own VPS unblocks horizontal API scaling. Each scaling action is independent of the others and requires no code changes — only infrastructure and configuration adjustments.
Infrastructure that is already K8s-ready. Every container is stateless, health-checked, and environment-configured. The migration from Docker Compose to Kubernetes Deployments is nearly 1:1. The operational investment in K8s is deferred until it genuinely earns its complexity, but the architecture does not need to change to support it.
The system described in this article runs on approximately $40/month of infrastructure (Hetzner CPX42 + CX23 + object storage) and handles thousands of concurrent users with comfortable headroom. Production-grade architecture does not require enterprise spending — it requires deliberate design.